
前文说了一下《六字说出微服务的本质》,在文末提到,初创团队不建议直接使用微服务,对于初创团队,最根本的是活下去,而想要使用微服务,需要有很多基础建设。本文就来说下,微服务都需要哪些基础建设。
需要说明的是,下面这些组件,都是基于服务太多这个前提。
微服务的出现是为了研发效能的提升:相同的人数可以处理更多的需求、维护更多的产品,可以更快的交付产品。基于这点,微服务的基础组件,就从解放人力,减少人为失误出发。
下面给出一张微服务基础组件的图片:
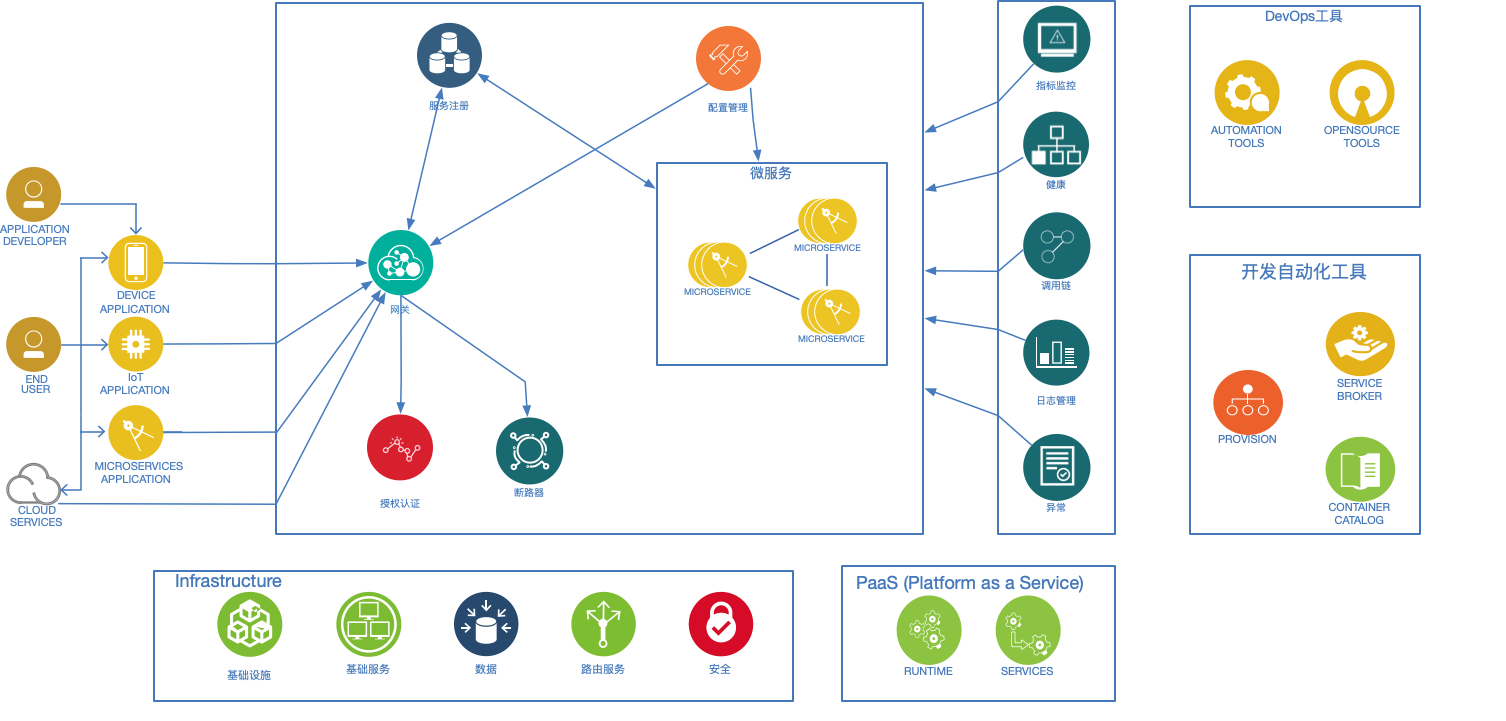
1 容器
1.1 运行容器
服务运行的容器是支持服务提供对外访问的基础,根据微服务的要求,每个服务单独运行的独立进程中,所需要的运行容器就需要小巧灵活,运行容器可以集成在运行环境中,或者能够集成在服务可执行包中。
在Java领域,各大厂商都有自己的web容器:WebLogic、JBoss、Tomcat、Jetty等。SpringBoot内嵌了Tomcat和Jetty,默认打包方式是FatJar,jar保证包含了服务运行所有的基础,可以支持微服务部署的基本要求。
1.2 部署容器
部署容器是服务运行的加成组件,容器的好处在于一套镜像可以支撑测试和生成部署。这样做可以避免测试环境没有问题,生产环境各种报错的情况。但是想要实现一套镜像到处运行,还需要集中配置的支持。
而且对于部署容器,最好有一套容器调度平台,这样能够更有效的使用资源。如果没有,可能用部署容器和普通部署方式,区别不是很大。
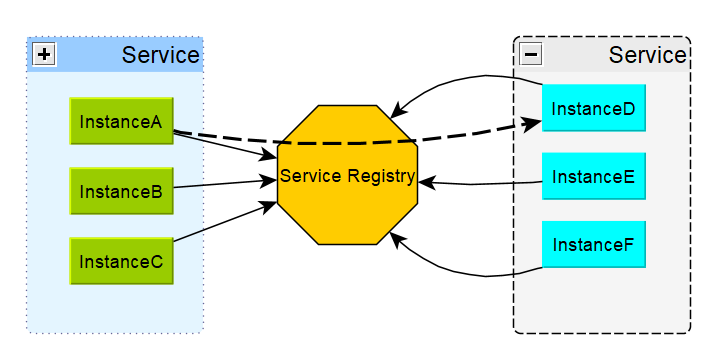
2 服务注册/发现
服务注册/发现是两个组件,彼此没有必然关系,但一般这两个组件会成对出现,解决同一个问题:服务地址动态变化的配置问题。
在单体架构时代,企业内部只有几个大系统,想要调用其他服务,只需要提前指定IP地址就行了。但是到了云原生时代,服务实例的网络地址都是动态分配的,想要提前指定IP是比较困难的。而且,在部署过程中,还会出现动态扩展、服务迁移、服务死亡等情况,服务实例也是动态变化。如果还是靠手工,不仅浪费时间,而且容易出错。
最好的办法就是,服务自己或通过代理人上报位置,然后客户端想要调用服务时,只需要从注册器中拿到一个可用的服务地址,直接调用,这就是服务注册/发现组件。
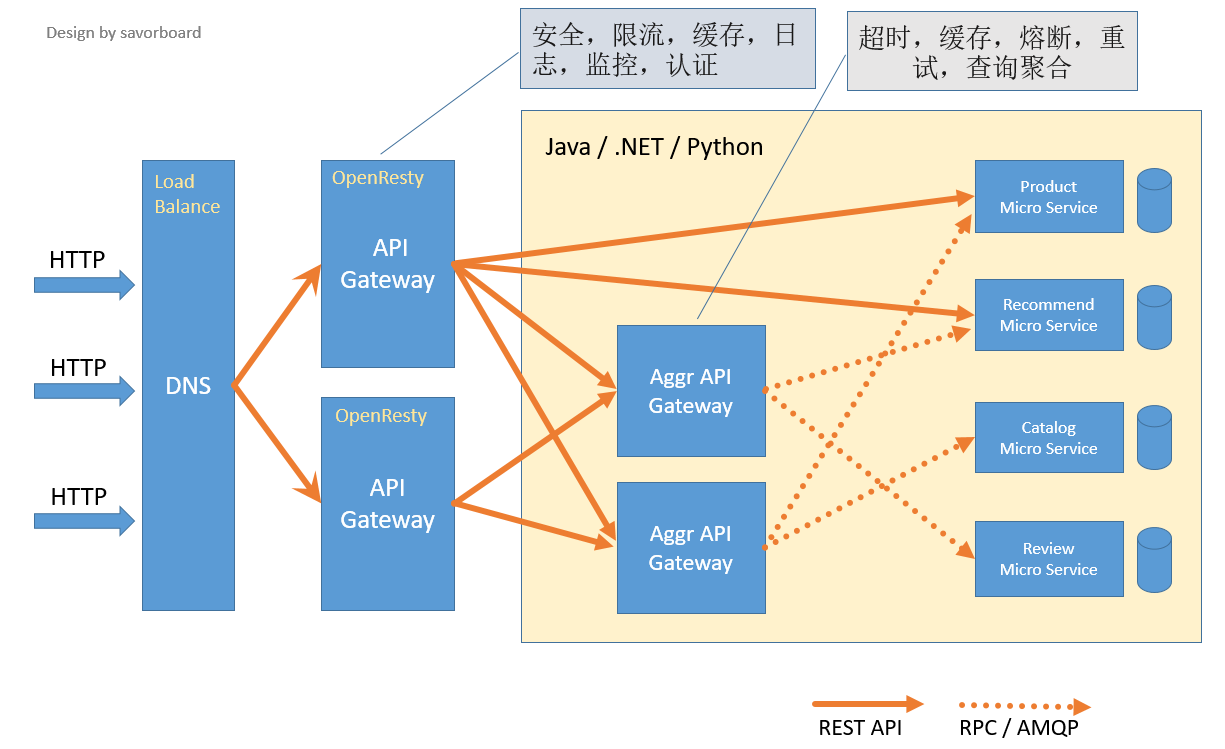
3 网关
在单体架构中,通常只有一组冗余或负载均衡的服务。在微服务架构中,每个服务都提供了一组细粒度的服务。对于一个普通的应用,可能需要调用多个不同的微服务,来获取全部的数据。这样做有三个缺点:
- 调用服务太多,将应用于后端服务捆绑,同时也造成第二个缺点
- 服务难以重构,随着时间推移,服务可能会出现合并或者拆分的情况,应用于服务捆绑在一起,就难以重构
- 后端服务对外暴露的协议不一致,可能对web不友好。虽然微服务要求服务之间使用轻量级通信,但是并没有强调必须使用HTTP协议。
这个时候,就需要有一个统一的出入口,来解耦应用于微服务,并且屏蔽内部细节,接收所有调用者请求。
目前在网关上有很多优秀的实践,将反向路由、安全认证、限流熔断、日志监控、灰度发布等功能放在网关上,将功能前置,简化微服务功能,让微服务团队可以更加专心于业务。
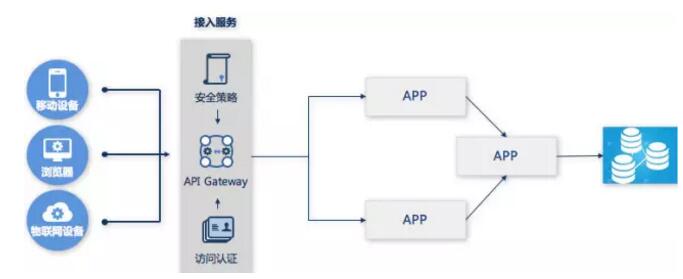
4 授权认证
安全第一,什么行业都是安全第一。
授权认证是两个概念:用户授权和安全认证。用户授权是指给指定用户授权访问资源,然后某个用户访问资源的时候,认证用户是否有访问资源的权限。两者配合,共同完成资源的安全保护。业界比较常用的是使用OAuth2协议实现授权认证。
5 配置管理
配置管理和前面说的服务注册/发现一样,都是为了解决服务太多,人工出差这个痛点的。
通常开发人员把配置放在配置文件中,这样配置不够规范,配置项追溯都比较麻烦。比较危险的是,涉及到用户名密码等一些安全性配置的,又不符合审计要求。而且,一旦需要大规模修改配置,改动时间长,改动之后就需要重新部署,可能对整个产品造成影响。所以就需要一个集中的配置管理服务。
6 日志收集
日志是记录服务运行情况的主要来源,也可以在发生异常情况时还原现场。但是随着服务的增多,日志分布在许多的服务器中,如果不进行聚合,在排查问题的时候,难上加难。
7 监控告警
监控告警不是微服务的专利,当服务集群或服务器达到一定规模,想要做到7*24不停机、不宕机提供服务,就需要监控告警。因为微服务的服务规模比较大,会将监控的必要性放大。
7.1 指标
通常监控指标是会从系统、应用、业务等几个维度进行:
- 系统监控:主要是监控物理机、虚拟机、操作系统的运行情况,主要指标包括CPU、内存、磁盘、网络等,其他的一些相关的数据包括物理机运行时间、操作系统版本、操作系统内核,这些也是排查问题的一些基本依据。这里还需要重点说一下网络,微服务都是通过网络调用或被调用,一旦网络出现问题,整个微服务集群都是不可用的,所以网络监控需要细化到流量、数据包、丢包、错报、连接数等指标。
- 应用监控:主要是监控应用的运行情况,包括应用运行时间、http服务端口、服务url、http服务响应码、http服务响应时间、SQL、缓存命中、TPS、QPS等。对于Java应用,还需要包括JVM运行情况:JDK版本、内存使用(堆内存、非堆内存等)、GC等Java虚拟机运行情况。
- 业务监控:主要是监控一些核心业务执行情况,对业务有一定的侵入性,各个服务的指标不同,各家监控方式也不同,通常是埋码。比如监控登录注册、商品信息、库存情况、下单、支付、发货等各个业务。
7.2 健康
一般健康检查是通过心跳检测进行的,通常会分为两种:
- 一种是建立TCP链接,执行ping/pong调用。这种方式需要服务中与监控系统建立TCP链接,需要在服务中嵌入监控组件,对服务有侵入。但是因为其执行效率高,而且针对性强,不会出现漏报的情况。
- 一种是监听服务端口,这种方式只需要在容器内或者虚拟机增加监控插件,对服务没什么侵入,但是由于端口可用和服务可用不是一个概念,所以会出现漏报的情况。
7.3 调用链
微服务之间彼此调用,整个的调用链路彼此交错,如果不加管理,很有可能演变成请求风暴。
调用链监控是为了分析系统依赖、请求耗时、请求瓶颈的一种方式。目前,市面上多数调用链监控组件都是基于Google Dapper开发的。下面给出调用链监控的原理示意图(因为调用链监控的内容比较多,所以会在后面单独开一章):
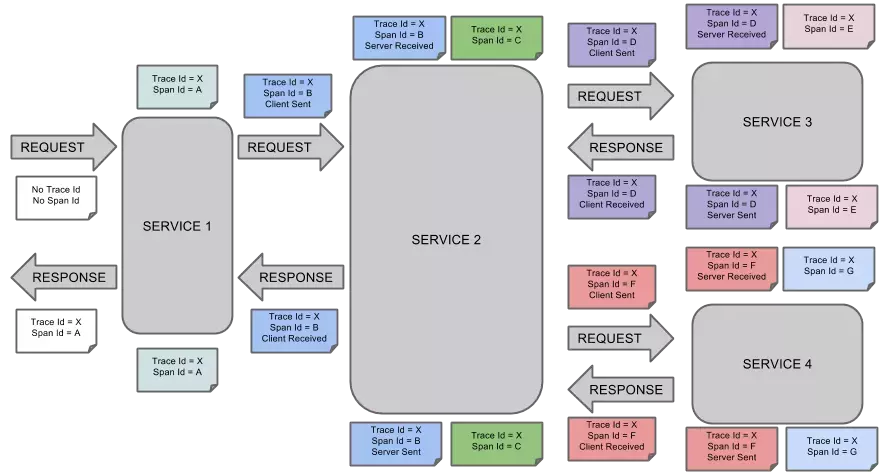
7.4 异常收集
异常分成两种,逻辑异常和行为异常。逻辑异常是说代码中存在异常逻辑,比如常见的NPE;行为异常时用户行为不可预期而出现的异常,这两种情况对系统都有一定危害。所以需要收集这些异常情况,并且能够定位异常发生的位置。异常信息收集主要是为了定位问题,所以上报的信息一定要全面而且容易定位。所以上报信息中需要保护异常码,可以自定义一定长度的字符串,便于定位位置。然后是要上报参数,用于还原现场。还要上报异常信息,用来分析异常情况。
8 最后
上面提到的组件,都是为了更好的管理微服务,减少人肉运维,减少人为失误。寥寥数语,难以道尽上述组件的优点,每个组件都需要单独细聊,这里就当是个引子。
推荐阅读
- 什么是微服务?
- 微服务编程范式
- 微服务的基建工作
- 微服务中服务注册和发现的可行性方案
- 从单体架构到微服务架构
- 如何在微服务团队中高效使用 Git 管理代码?
- 关于微服务系统中数据一致性的总结
- 实现DevOps的三步工作法
- 系统设计系列之如何设计一个短链服务
- 系统设计系列之任务队列
- 软件架构-缓存技术
- 软件架构-事件驱动架构
个人主页: https://www.howardliu.cn
个人博文: 微服务的基建工作
CSDN主页: http://blog.csdn.net/liuxinghao
CSDN博文: 微服务的基建工作
