你好,我是看山。
本文收录在 《从小工到专家的 Java 进阶之旅》 系列专栏中。
概述
从 2017 年开始,Java 版本更新遵循每六个月发布一次的节奏,LTS版本则每两年发布一次,以快速验证新特性,推动 Java 的发展。
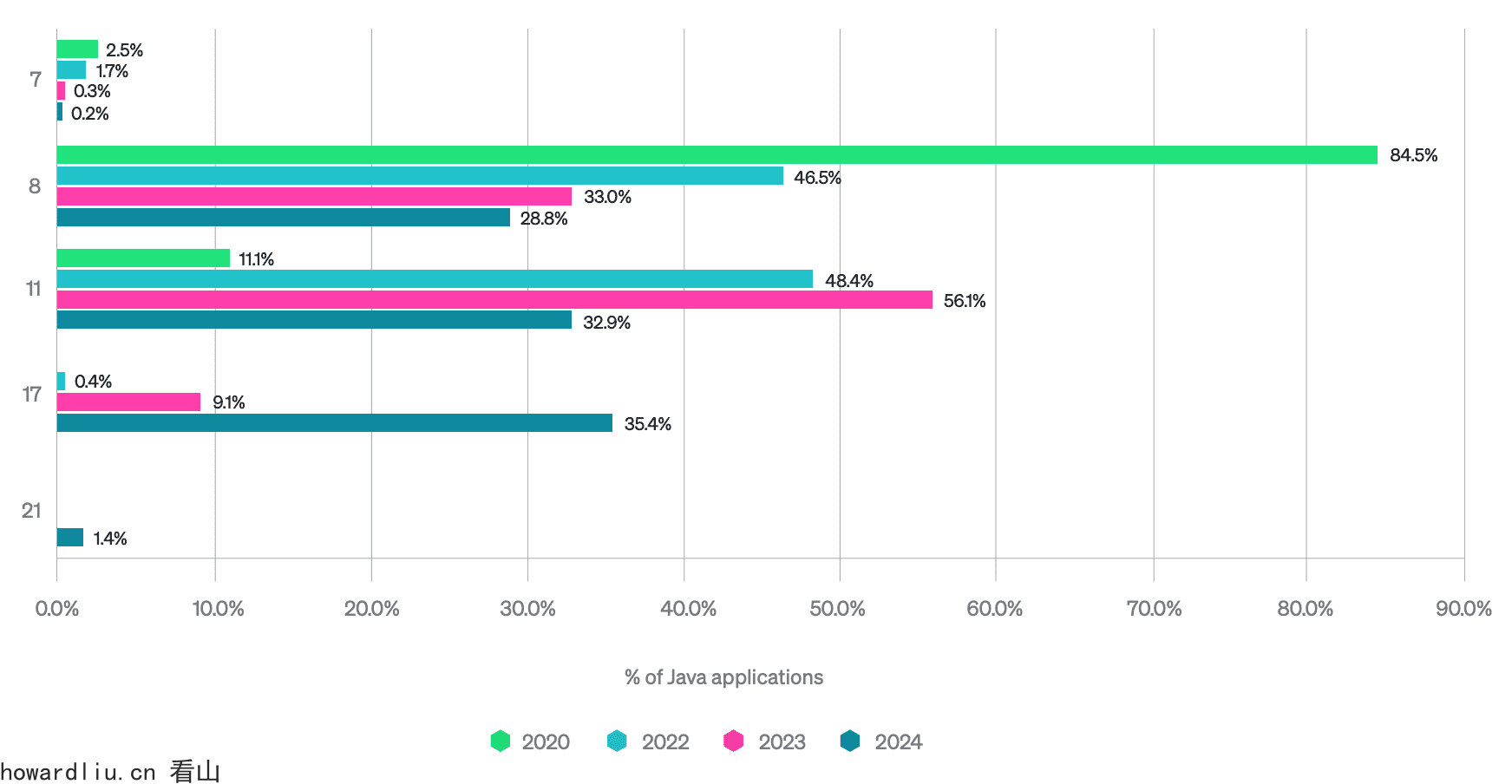
数据来源2024 State of the Java Ecosystem
有意思的特性
可以从 《从小工到专家的 Java 进阶之旅》 系列专栏中查看各个版本的特性。
大家都很熟悉的特性
Java8中的Lambda表达式、Stream流、Optional是大版本特性,Java8是2014年发布,已有十年历史了。大家应该分厂熟悉了,这里不在赘述。推荐两篇文章:
补全技能树
Record 类型(Java 16)
Java新增了一个关键字record,它是定义不可变数据类型封装类的关键字,主要用在特定领域类上。
我们都知道,在Java开发中,我们需要定义POJO作为数据存储对象,根据规范,POJO中除了属性是个性化的,其他的比如getter、setter、equals、hashCode、toString都是模板化的写法,所以为了简便,很多类似Lombok的组件提供Java类编译时增强,通过在类上定义@Data注解自动添加这些模板化方法。在Java14中,我们可以直接使用record解决这个问题。
比如,我们定义一个Person类:
public record Person(String name, String address) {}
我们转换为之前的定义会是一坨下面这种代码:
public final class PersonBefore { private final String name; private final String address; public PersonBefore(String name, String address) { this.name = name; this.address = address; } public String name() { return name; } public String address() { return address; } @Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } PersonBefore14 that = (PersonBefore14) o; return Objects.equals(name, that.name) && Objects.equals(address, that.address); } @Override public int hashCode() { return Objects.hash(name, address); } @Override public String toString() { return "PersonBefore{" + "name='" + name + '\'' + ", address='" + address + '\'' + '}'; }}
我们可以发现Record类有如下特征:
- 一个构造方法
- getter方法名与属性名相同
- 有
equals()、hashCode()方法 - 有
toString()方法 - 类对象和属性被
final修饰,所以构造函数是包含所有属性的,而且没有setter方法
在Class类中也新增了对应的处理方法:
getRecordComponents():返回一组java.lang.reflect.RecordComponent对象组成的数组,该数组的元素与Record类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个RecordComponent中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。isRecord():返回所在类是否是 Record 类型,如果是,则返回 true。
看起来,Record类和Enum很像,都是一定的模板类,通过语法糖定义,在Java编译过程中,将其编译成特定的格式,功能很好,但如果没有习惯使用,可能会觉得限制太多。
密封类和接口(Java 17)
目前,Java 没有提供对继承的细粒度控制,只有 public、protected、private、包内控制四种非常粗粒度的控制方式。
为此,密封类的目标是允许单个类声明哪些类型可以用作其子类型。这也适用于接口,并确定哪些类型可以实现它们。该功能特性新增了sealed和non-sealed修饰符和permits关键字。
我们可以做如下定义:
public sealed class Person permits Student, Worker, Teacher {}public sealed class Student extends Person permits Pupil, JuniorSchoolStudent, HighSchoolStudent, CollegeStudent, GraduateStudent {}public final class Pupil extends Student {}public non-sealed class Worker extends Person {}public class OtherClass extends Worker {}public final class Teacher extends Person {}
我们可以先定义一个sealed修饰的类Person,使用permits指定被继承的子类,这些子类必须是使用final或sealed或non-sealed修饰的类。其中Student是使用sealed修饰,所以也需要使用permits指定被继承的子类。Worker类使用non-sealed修饰,成为普通类,其他类都可以继承它。Teacher使用final修饰,不可再被继承。
从类图上看没有太多区别:
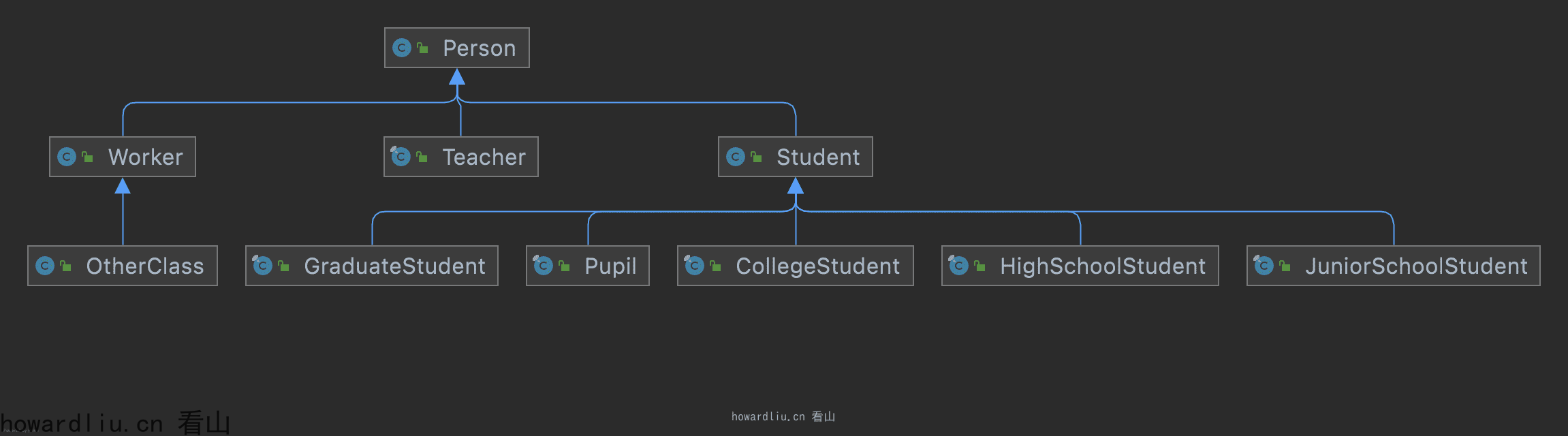
但是从功能特性上,起到了很好的约束作用,我们可以放心大胆的定义可以公开使用,但又不想被非特定类继承的类了。
全新的 HTTP 客户端(Java 11)
老版 HTTP 客户端存在很多问题,大家开发的时候基本上都是使用第三方 HTTP 库,比如 Apache HttpClient、Netty、Jetty 等。
新版 HTTP 客户端的目标很多,毕竟这么多珠玉在前,如果还是做成一坨,指定是要被笑死的。所以新版 HTTP 客户端列出了 16 个目标,包括简单易用、打印关键信息、WebSocket、HTTP/2、HTTPS/TLS、良好的性能、非阻塞 API 等等。
@Testvoid testHttpClient() throws IOException, InterruptedException { final HttpClient httpClient = HttpClient.newBuilder() .version(HttpClient.Version.HTTP_2) .connectTimeout(Duration.ofSeconds(20)) .build(); final HttpRequest httpRequest = HttpRequest.newBuilder() .GET() .uri(URI.create("https://www.howardliu.cn/robots.txt")) .build(); final HttpResponse<String> httpResponse = httpClient.send(httpRequest, BodyHandlers.ofString()); final String responseBody = httpResponse.body(); assertTrue(responseBody.contains("Allow"));}
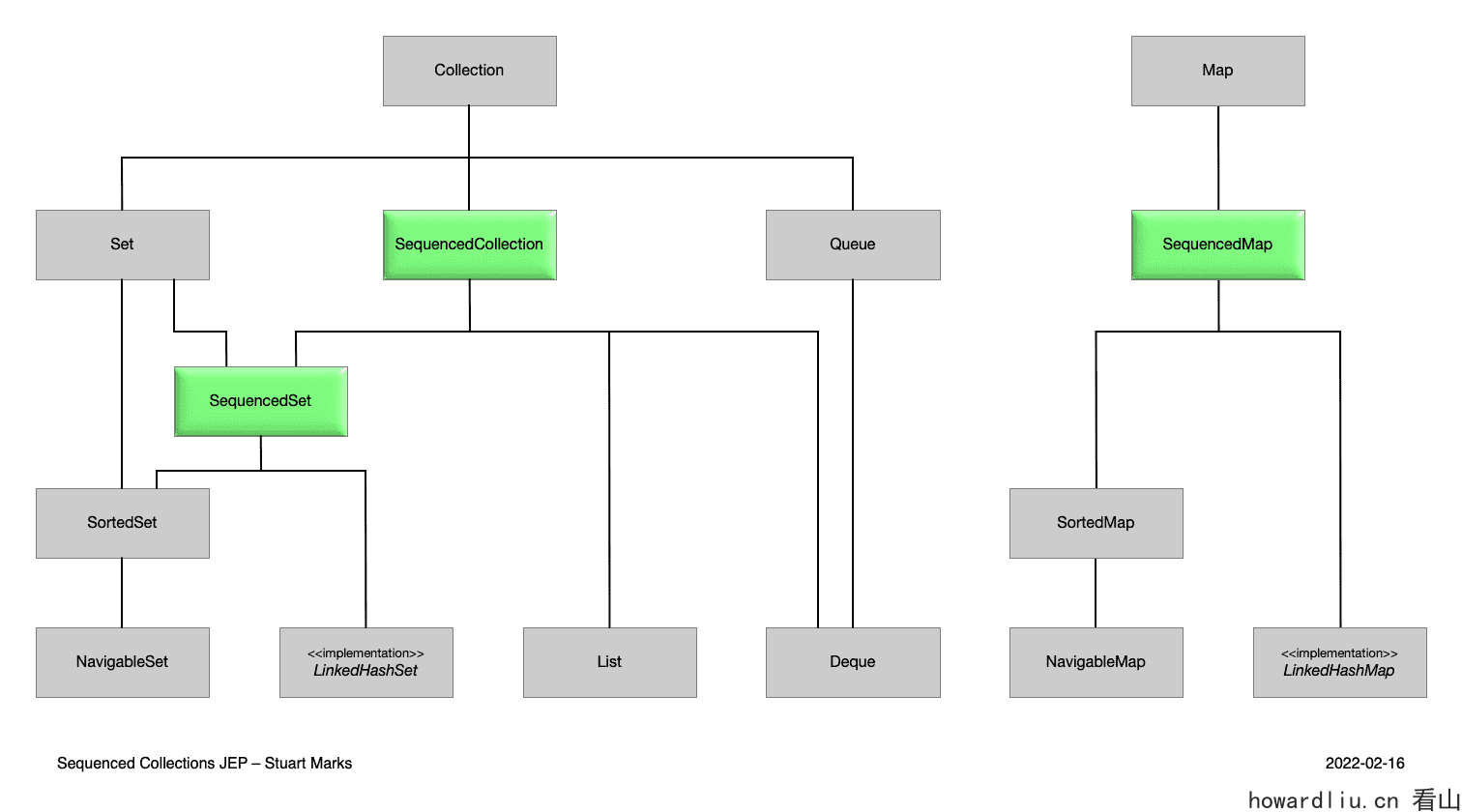
有序集合(Java 21)
有序集合是Java21版本中引入的一个新特性,旨在为Java集合框架添加对有序集合的支持。
有序集合是一种具有定义好的元素访问顺序的集合类型,它允许以一致的方式访问和处理集合中的元素,无论是从第一个元素到最后一个元素,还是从最后一个元素到第一个元素。
在 Java 中,集合类库非常重要且使用频率非常高,但是缺乏一种能够表示具有定义好的元素访问顺序的集合类型。
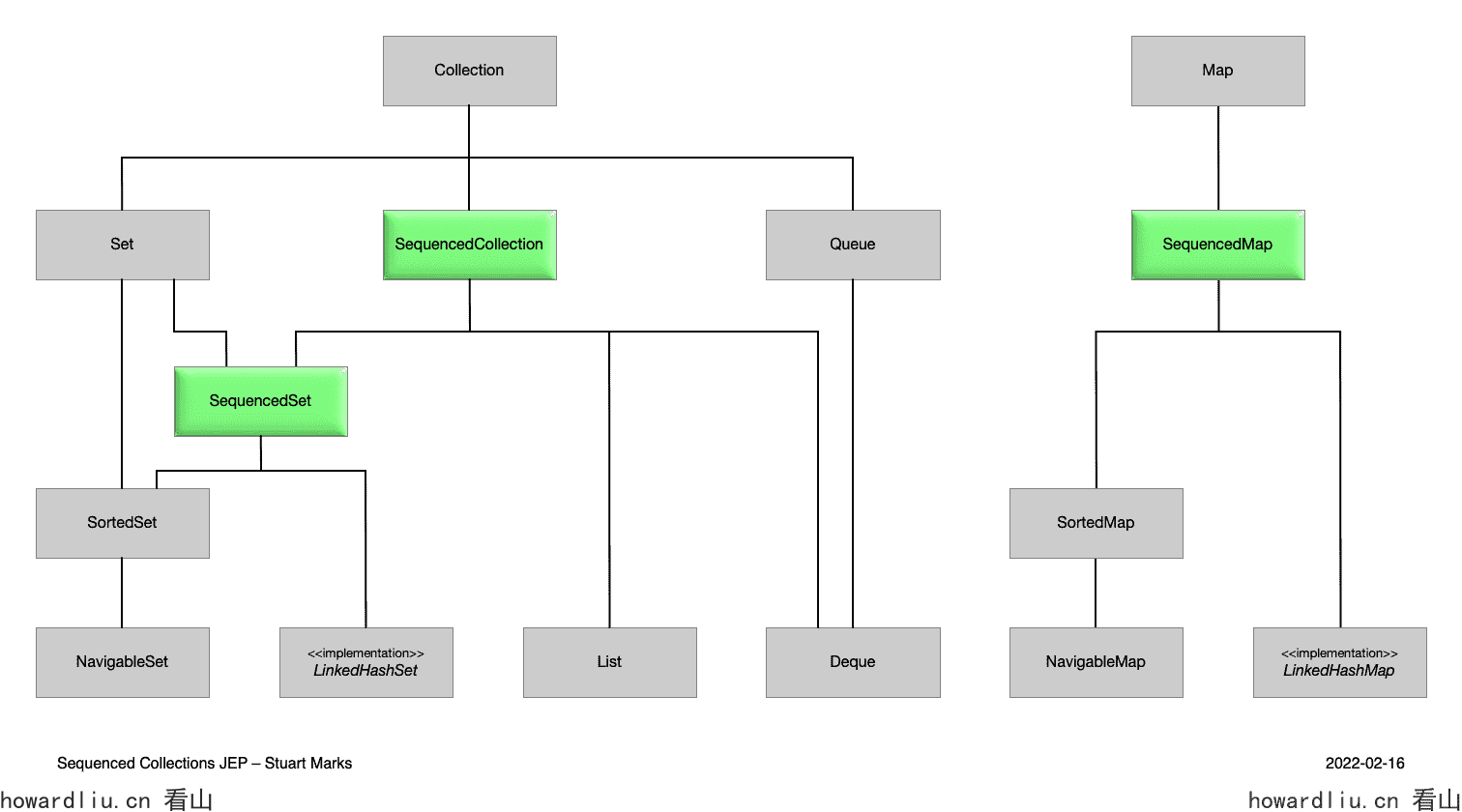
例如,List和Deque都定义了元素的访问顺序,但它们的共同父接口Collection却没有。同样,Set不定义元素的访问顺序,其子类型如HashSet也没有定义,但子类型如SortedSet和LinkedHashSet则有定义。因此,支持访问顺序的功能散布在整个类型层次结构中,使得在API中表达某些有用的概念变得困难。Collection太通用,将此类约束留给文档规范,可能导致难以调试的错误。
而且,虽然某些集合有顺序操作方法,但是却不尽相同,比如
| First element | Last element |
|---|
| List | list.get(0) | list.get(list.size() - 1) |
| Deque | deque.getFirst() | deque.getLast() |
| SortedSet | sortedSet.first() | sortedSet.last() |
| LinkedHashSet | linkedHashSet.iterator().next() | 缺失 |
提供了有序集合SequencedCollection、SequencedSet、SequencedMap:
interface SequencedCollection<E> extends Collection<E> { // new method SequencedCollection<E> reversed(); // methods promoted from Deque void addFirst(E); void addLast(E); E getFirst(); E getLast(); E removeFirst(); E removeLast();}interface SequencedSet<E> extends Set<E>, SequencedCollection<E> { SequencedSet<E> reversed(); // covariant override}interface SequencedMap<K,V> extends Map<K,V> { // new methods SequencedMap<K,V> reversed(); SequencedSet<K> sequencedKeySet(); SequencedCollection<V> sequencedValues(); SequencedSet<Entry<K,V>> sequencedEntrySet(); V putFirst(K, V); V putLast(K, V); // methods promoted from NavigableMap Entry<K, V> firstEntry(); Entry<K, V> lastEntry(); Entry<K, V> pollFirstEntry(); Entry<K, V> pollLastEntry();}
SequencedCollection的reversed()方法提供了一个原始集合的反向视图。任何对原始集合的修改都会在视图中可见。如果允许,视图中的修改会写回到原始集合。
我们看一个例子,假设我们有一个LinkedHashSet,现在我们想要获取它的反向视图并以反向顺序遍历它:
LinkedHashSet<Integer> linkedHashSet = new LinkedHashSet<>(Arrays.asList(3, 2, 1));// 获取反向视图SequencedCollection<Integer> reversed = linkedHashSet.reversed();// 反向遍历System.out.println("原始数据:" + linkedHashSet);System.out.println("反转数据:" + reversed);// 运行结果:// 原始数据:[3, 2, 1]// 反转数据:[1, 2, 3]
这些方法都是便捷方法,内部数据结构没有变化,其实本质也是原来的用法。比如ArrayList中的getFirst和getLast方法:
/** * {@inheritDoc} * * @throws NoSuchElementException {@inheritDoc} * @since 21 */public E getFirst() { if (size == 0) { throw new NoSuchElementException(); } else { return elementData(0); }}/** * {@inheritDoc} * * @throws NoSuchElementException {@inheritDoc} * @since 21 */public E getLast() { int last = size - 1; if (last < 0) { throw new NoSuchElementException(); } else { return elementData(last); }}
提升幸福感的特性
局部变量类型推断(Java 10)
// 以前的写法Map<String, List<ProcSequenceFlow>> sourceMap = sequenceFlowList.stream() .collect(Collectors.groupingBy(ProcSequenceFlow::getSourceRef));// 现在的写法var sourceMap2 = sequenceFlowList.stream() .collect(Collectors.groupingBy(ProcSequenceFlow::getSourceRef));
Switch表达式(Java 14)
我们以“判断是否工作日”的例子展示一下,在Java14之前:
@Testvoid testSwitch() { final DayOfWeek day = DayOfWeek.from(LocalDate.now()); String typeOfDay = ""; switch (day) { case MONDAY: case TUESDAY: case WEDNESDAY: case THURSDAY: case FRIDAY: typeOfDay = "Working Day"; break; case SATURDAY: case SUNDAY: typeOfDay = "Rest Day"; break; } Assertions.assertFalse(typeOfDay.isEmpty());}
在Java14中:
@Testvoid testSwitchExpression() { final DayOfWeek day = DayOfWeek.SATURDAY; final String typeOfDay = switch (day) { case MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY -> { System.out.println("Working Day: " + day); yield "Working Day"; } case SATURDAY, SUNDAY -> "Day Off"; }; Assertions.assertEquals("Day Off", typeOfDay);}
注意看,例子中我们使用了两种写法,一种是通过yield关键字表示返回结果,一种是在->之后直接返回。
文本块(Java 15)
直接上代码
@Testvoid testTextBlock() { final String singleLine = "你好,我是看山,公众号「看山的小屋」。这行没有换行,而且我的后面多了一个空格 这次换行了"; final String textBlockSingleLine = """ 你好,我是看山,公众号「看山的小屋」。\ 这行没有换行,而且我的后面多了一个空格\s 这次换行了"""; Assertions.assertEquals(singleLine, textBlockSingleLine);}
字符串模板(预览)
字符串模板通过将文本和嵌入式表达式结合在一起,使得Java程序能够以一种更加直观和安全的方式构建字符串。
与传统的字符串拼接(使用+操作符)、StringBuilder或String.format 等方法相比,字符串模板提供了一种更加清晰和安全的字符串构建方式。
特别是当字符串需要从用户提供的值构建并传递给其他系统时(例如,构建数据库查询),使用字符串模板可以有效地验证和转换模板及其嵌入表达式的值,从而提高Java程序的安全性。
让我们通过代码看一下这个特性的魅力:
public static void main(String[] args) { // 拼装变量 String name = "看山"; String info = STR. "My name is \{ name }" ; assert info.equals("My name is 看山"); // 拼装变量 String firstName = "Howard"; String lastName = "Liu"; String fullName = STR. "\{ firstName } \{ lastName }" ; assert fullName.equals("Howard Liu"); String sortName = STR. "\{ lastName }, \{ firstName }" ; assert sortName.equals("Liu, Howard"); // 模板中调用方法 String s2 = STR. "You have a \{ getOfferType() } waiting for you!" ; assert s2.equals("You have a gift waiting for you!"); Request req = new Request("2017-07-19", "09:15", "https://www.howardliu.cn"); // 模板中引用对象属性 String s3 = STR. "Access at \{ req.date } \{ req.time } from \{ req.address }" ; assert s3.equals("Access at 2017-07-19 09:15 from https://www.howardliu.cn"); LocalTime now = LocalTime.now(); String markTime = DateTimeFormatter .ofPattern("HH:mm:ss") .format(now); // 模板中调用方法 String time = STR. "The time is \{ // The java.time.format package is very useful DateTimeFormatter .ofPattern("HH:mm:ss") .format(now) } right now" ; assert time.equals("The time is " + markTime + " right now"); // 模板嵌套模板 String[] fruit = {"apples", "oranges", "peaches"}; String s4 = STR. "\{ fruit[0] }, \{ STR. "\{ fruit[1] }, \{ fruit[2] }" }" ; assert s4.equals("apples, oranges, peaches"); // 模板与文本块结合 String title = "My Web Page"; String text = "Hello, world"; String html = STR. """ <html> <head> <title>\{ title }</title> </head> <body> <p>\{ text }</p> </body> </html> """ ; assert html.equals(""" <html> <head> <title>My Web Page</title> </head> <body> <p>Hello, world</p> </body> </html> """); // 带格式化的字符串模板 record Rectangle(String name, double width, double height) { double area() { return width * height; } } Rectangle[] zone = new Rectangle[] { new Rectangle("Alfa", 17.8, 31.4), new Rectangle("Bravo", 9.6, 12.4), new Rectangle("Charlie", 7.1, 11.23), }; String table = FMT. """ Description Width Height Area %-12s\{ zone[0].name } %7.2f\{ zone[0].width } %7.2f\{ zone[0].height } %7.2f\{ zone[0].area() } %-12s\{ zone[1].name } %7.2f\{ zone[1].width } %7.2f\{ zone[1].height } %7.2f\{ zone[1].area() } %-12s\{ zone[2].name } %7.2f\{ zone[2].width } %7.2f\{ zone[2].height } %7.2f\{ zone[2].area() } \{ " ".repeat(28) } Total %7.2f\{ zone[0].area() + zone[1].area() + zone[2].area() } """; assert table.equals(""" Description Width Height Area Alfa 17.80 31.40 558.92 Bravo 9.60 12.40 119.04 Charlie 7.10 11.23 79.73 Total 757.69 """);}public static String getOfferType() { return "gift";}record Request(String date, String time, String address) {}
这个功能当前是第一次预览,在Java22第二次预览,Java23的8.12版本中还没有展示字符串模板的第三次预览(JEP 465: String Templates),还不能确定什么时候可以正式用上。
模式匹配
instanceof模式匹配(Java 16)
instanceof主要用来检查对象类型,作为类型强转前的安全检查。
比如:
@Testvoid test() { final Object obj1 = "Hello, World!"; int result = 0; if (obj1 instanceof String) { String str = (String) obj1; result = str.length(); } else if (obj1 instanceof Number) { Number num = (Number) obj1; result = num.intValue(); } Assertions.assertEquals(13, result);}
可以看到,我们每次判断类型之后,需要声明一个判断类型的变量,然后将判断参数强制转换类型,赋值给新声明的变量。
这种写法显得繁琐且多余。
instanceof改进后:
@Testvoid test1() { final Object obj1 = "Hello, World!"; int result = 0; if (obj1 instanceof String str) { result = str.length(); } else if (obj1 instanceof Number num) { result = num.intValue(); } Assertions.assertEquals(13, result);}
不仅如此,instanceof模式匹配的作用域还可以扩展。在if条件判断中,我们都知道&&与判断是会执行所有的表达式,所以使用instanceof模式匹配定义的局部变量继续判断。
比如:
if (obj1 instanceof String str && str.length() > 20) { result = str.length();}
与原来的写法对比,新的写法代码更加简洁、可读性更高,能够提出很多冗余繁琐的代码,非常实用的一个特性。
switch模式匹配(Java 21)
switch模式匹配是一个非常赞的功能,可以在选择器表达式使用基础判断和任意引用类型,包括instanceof操作符。这意味着可以更灵活地使用对象、数组、列表等复杂数据结构作为switch语句的基础,从而简化代码并提高可读性。
switch模式匹配允许在switch语句中使用模式来测试表达式,每个模式都有特定的动作,从而可以简洁、安全地表达复杂的数据导向查询。
通过代码看下switch模式匹配的魅力;
static String formatValue(Object obj) { return switch (obj) { case null -> "null"; case Integer i -> String.format("int %d", i); case Long l -> String.format("long %d", l); case Double d -> String.format("double %f", d); case String s -> String.format("String %s", s); case Person(String name, String address) -> String.format("Person %s %s", name, address); default -> obj.toString(); };}public record Person(String name, String address) {}public static void main(String[] args) { System.out.println(formatValue(10)); System.out.println(formatValue(20L)); System.out.println(formatValue(3.14)); System.out.println(formatValue("Hello")); System.out.println(formatValue(null)); System.out.println(formatValue(new Person("Howard", "Beijing")));}// 运行结果// int 10// long 20// double 3.140000// String Hello// null// Person Howard Beijing
Record 模式(Java 21)
Record是Java16正式发布的基础类型,提供不可变对象的简单实现(其实就是Java Bean,但是省略一堆的getter、setter、hashcode、equals、toString等方法)。
Record模式,主要是使Record类型可以直接在instanceof和switch模式匹配中使用。
我们一起看个示例,比如有下面几个基础元素:
// 颜色enum Color { RED, GREEN, BLUE}// 点record Point(int x, int y) {}// 带颜色的点record ColoredPoint(Point p, Color color) {}// 正方形record Square(ColoredPoint upperLeft, ColoredPoint lowerRight) {}
我们分别通过instanceof模式匹配和switch模式匹配判断输入参数的类型,打印不同的格式:
private static void instancePatternsAndPrint(Object o) { if (o instanceof Square(ColoredPoint upperLeft, ColoredPoint lowerRight)) { System.out.println("Square类型:" + upperLeft + " " + lowerRight); } else if (o instanceof ColoredPoint(Point(int x, int y), Color color)) { System.out.println("ColoredPoint类型:" + x + " " + y + " " + color); } else if (o instanceof Point p) { System.out.println("Point类型:" + p); }}private static void switchPatternsAndPrint(Object o) { switch (o) { case Square(ColoredPoint upperLeft, ColoredPoint lowerRight) -> { System.out.println("Square类型:" + upperLeft + " " + lowerRight); } case ColoredPoint(Point(int x, int y), Color color) -> { System.out.println("ColoredPoint类型:" + x + " " + y + " " + color); } case Point p -> { System.out.println("Point类型:" + p); } default -> throw new IllegalStateException("Unexpected value: " + o); }}
我们通过main方法执行下:
public static void main(String[] args) { var p = new Point(1, 2); var cp1 = new ColoredPoint(p, Color.RED); var cp2 = new ColoredPoint(p, Color.GREEN); var square = new Square(cp1, cp2); instancePatternsAndPrint(square); instancePatternsAndPrint(cp1); instancePatternsAndPrint(p); switchPatternsAndPrint(square); switchPatternsAndPrint(cp1); switchPatternsAndPrint(p);}// 结果是://// Square类型:ColoredPoint[p=Point[x=1, y=2], color=RED] ColoredPoint[p=Point[x=1, y=2], color=GREEN]// ColoredPoint类型:1 2 RED// Point类型:Point[x=1, y=2]//// Square类型:ColoredPoint[p=Point[x=1, y=2], color=RED] ColoredPoint[p=Point[x=1, y=2], color=GREEN]// ColoredPoint类型:1 2 RED// Point类型:Point[x=1, y=2]
是不是很简洁,就像Java8提供的Lambda表达式一样,很丝滑。
灵活的构造函数主体(预览特性)
我们都知道,在子类的构造函数中,比如通过super(……)调用父类,在super之前是不允许有其他语句的。
大部分的时候这种限制都没问题,但是有时候不太灵活。如果想在super之前加上一些子类特有逻辑,比如想统计下子类构造耗时,就得重写一遍父类的实现。
除了有损灵活性,这种重写的做法也会造成父子类之间的关系变得奇怪。假设父类是SDK中的一个类,SDK升级时在父类构造函数增加了一些逻辑,我们项目中是无法继承这些逻辑的,某次需要升级SDK(比如低版本有安全风险),验证不完整的情况下,就很容易出现bug。
该特性的目标是提高构造函数的可读性和可预测性,同时保持构造函数调用的自上而下的规则。通过允许在显式调用 super() 或 this() 前初始化字段,从而实现更灵活的构造函数主体。这一变化使得代码更具表现力。
我们看下示例代码:
public class PositiveBigInteger extends BigInteger { public PositiveBigInteger(long value) { if (value <= 0) { throw new IllegalArgumentException("non-positive value"); } super(value); }}
永远学不完的多线程
虚拟线程(Java 21)
虚拟线程是一种轻量级的线程实现,旨在显著降低编写、维护和观察高吞吐量并发应用程序的难度。它们占用的资源少,不需要被池化,可以创建大量虚拟线程,特别适用于IO密集型任务,因为它们可以高效地调度大量虚拟线程来处理并发请求,从而显著提高程序的吞吐量和响应速度。
虚拟线程有下面几个特点:
- 轻量级:虚拟线程是JVM内部实现的轻量级线程,不需要操作系统内核参与,创建和上下文切换的成本远低于传统的操作系统线程(即平台线程),且占用的内存资源较少。
- 减少CPU时间消耗:由于虚拟线程不依赖于操作系统平台线程,因此在进行线程切换时耗费的CPU时间会大大减少,从而提高了程序的执行效率。
- 简化多线程编程:虚拟线程通过结构化并发API来简化多线程编程,使得开发者可以更容易地编写、维护和观察高吞吐量并发应用程序。
- 适用于大量任务场景:虚拟线程非常适合需要创建和销毁大量线程的任务、需要执行大量计算的任务(如数据处理、科学计算等)以及需要实现任务并行执行以提高程序性能的场景。
- 提高系统吞吐量:通过对虚拟线程的介绍和与Go协程的对比,可以看出虚拟线程能够大幅提高系统的整体吞吐量。
不考虑虚拟线程实现原理,对开发者而言,使用体验上与传统线程几乎没有区别。
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { IntStream.range(0, 10_000).forEach(i -> { executor.submit(() -> { Thread.sleep(Duration.ofSeconds(1)); System.out.println(Thread.currentThread().getName() + ": " + i); return i; }); });}Thread.startVirtualThread(() -> { System.out.println("Hello from a virtual thread[Thread.startVirtualThread]");});final ThreadFactory factory = Thread.ofVirtual().factory();factory.newThread(() -> { System.out.println("Hello from a virtual thread[ThreadFactory.newThread]"); }) .start();
虚拟线程为了降低使用门槛,直接提供了与原生线程类似的方法:
Executors.newVirtualThreadPerTaskExecutor(),可以像普通线程池一样创建虚拟线程。Thread.startVirtualThread,通过工具方法直接创建并运行虚拟线程。Thread.ofVirtual().factory().newThread(),另一个工具方法可以创建并运行虚拟线程。Thread还有一个ofPlatform()方法,用来构建普通线程。
需要注意的是,虚拟线程适用于IO密集场景,而非CPU密集的场景。
作用域值(预览特性)
作用域值(Scoped Values),旨在促进在线程内和线程间共享不可变数据。这一特性为现代 Java 应用程序提供了一种更高效和安全的替代传统 ThreadLocal 机制的方法,尤其是在并发编程的背景下。
作用域值允许开发者定义一个变量,该变量可以在特定的作用域内访问,包括当前线程及其创建的任何子线程。这一机制特别适用于在方法调用链中隐式传递数据,而无需在方法签名中添加额外的参数。
作用域值的主要特点:
- 不可变性:作用域值是不可变的,这意味着一旦设置,其值就不能更改。这种不可变性减少了并发编程中意外副作用的风险。
- 作用域生命周期:作用域值的生命周期仅限于 run 方法定义的作用域。一旦执行离开该作用域,作用域值将不再可访问。
- 继承性:子线程会自动继承父线程的作用域值,从而允许在线程边界间无缝共享数据。
在之前,在多线程间传递数据,我们会使用ThreadLocal来保存当前线程变量,用完需要手动清理,如果忘记清理或者使用不规范,可能导致内存泄漏等问题。作用域值通过自动管理生命周期和内存,减少了这种风险。
我们一起看下作用域值的使用:
// 声明一个作用域值用于存储用户名public final static ScopedValue<String> USERNAME = ScopedValue.newInstance();private static final Runnable printUsername = () -> System.out.println(Thread.currentThread().threadId() + " 用户名是 " + USERNAME.get());public static void main(String[] args) throws Exception { // 将用户名 "Bob" 绑定到作用域并执行 Runnable ScopedValue.where(USERNAME, "Bob").run(() -> { printUsername.run(); new Thread(printUsername).start(); }); // 将用户名 "Chris" 绑定到另一个作用域并执行 Runnable ScopedValue.where(USERNAME, "Chris").run(() -> { printUsername.run(); new Thread(() -> { new Thread(printUsername).start(); printUsername.run(); }).start(); }); // 检查在任何作用域外 USERNAME 是否被绑定 System.out.println("用户名是否被绑定: " + USERNAME.isBound());}
写起来干净利索,而且功能更强。
结构化并发API(预览特性)
结构化并发API(Structured Concurrency API)旨在简化多线程编程,通过引入一个API来处理在不同线程中运行的多个任务作为一个单一工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观测性。这是一个处于孵化阶段的API。
结构化并发API提供了明确的语法结构来定义子任务的生命周期,并启用一个运行时表示线程间的层次结构。这有助于实现错误传播和取消以及并发程序的有意义观察。
Java使用异常处理机制来管理运行时错误和其他异常。当异常在代码中产生时,如何被传递和处理的过程称为异常传播。
在结构化并发环境中,异常可以通过显式地从当前环境中抛出并传播到更大的环境中去处理。
在Java并发编程中,非受检异常的处理是程序健壮性的重要组成部分。特别是对于非受检异常的处理,这关系到程序在遇到错误时是否能够优雅地继续运行或者至少提供有意义的反馈。
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { var task1 = scope.fork(() -> { Thread.sleep(1000); return "Result from task 1"; }); var task2 = scope.fork(() -> { Thread.sleep(2000); return "Result from task 2"; }); scope.join(); scope.throwIfFailed(RuntimeException::new); System.out.println(task1.get()); System.out.println(task2.get());} catch (Exception e) { e.printStackTrace();}
在这个例子中,handle()方法使用StructuredTaskScope来并行执行两个子任务:task1和task2。通过使用try-with-resources语句自动管理资源,并确保所有子任务都在try块结束时正确完成或被取消。这种方式使得线程的生命周期和任务的逻辑结构紧密相关,提高了代码的清晰度和错误处理的效率。使用 StructuredTaskScope 可以确保一些有价值的属性:
- 错误处理与短路:如果task1或task2子任务中的任何一个失败,另一个如果尚未完成则会被取消。(这由 ShutdownOnFailure 实现的关闭策略来管理;还有其他策略可能)。
- 取消传播:如果在运行上面方法的线程在调用 join() 之前或之中被中断,则线程在退出作用域时会自动取消两个子任务。
- 清晰性:设置子任务,等待它们完成或被取消,然后决定是成功(并处理已经完成的子任务的结果)还是失败(子任务已经完成,因此没有更多需要清理的)。
- 可观察性:线程转储清楚地显示了任务层次结构,其中运行task1或task2的线程被显示为作用域的子任务。
上面的示例能够很好的解决我们的一个痛点,有两个可并行的任务A和B,A+B才是完整结果,任何一个失败,另外一个也不需要成功,结构化并发API就可以很容易的实现这个逻辑。
垃圾收集器
G1(Java 9)
G1垃圾收集器(Garbage-First Garbage Collector,简称G1 GC)是一种专为服务器端应用设计的垃圾收集器,特别适用于具有多核处理器和大内存的机器。它在Java 9中成为默认的垃圾收集器。
- 分区机制:G1将整个堆空间划分为若干个大小相等的独立区域(Region),每个Region的大小根据堆的实际大小而定,通常控制在1MB到32MB之间。这种分区的思想弱化了传统的分代概念,使得垃圾收集更加灵活和高效。
- 垃圾回收策略:G1采用混合垃圾回收策略(Mix GC),不仅回收新生代中的所有Region,还会回收部分老年代中的Region。这种策略的目标是在保证停顿时间不超过预期的情况下,尽可能地回收更多的垃圾对象。
- 并行与并发:G1能够充分利用CPU、多核环境下的硬件优势,使用多个CPU核心来缩短Stop-The-World停顿时间。部分其他收集器需要停顿Java线程执行的GC动作,但G1可以通过并发的方式让Java程序继续运行。
- 高吞吐量与低延迟:G1的主要目标是在满足高吞吐量的同时,尽可能减少GC停顿时间。通过跟踪各个Region中的垃圾堆积情况,每次根据设置的垃圾回收时间,优先处理优先级最高的区域,避免一次性清理整个新生代或整个老年代的垃圾。
G1垃圾收集器非常适合大尺寸堆内存的应用场景,特别是在多处理器环境下。它的设计目标是能够在有限的时间内获取尽可能高的收集效率,并且避免内存碎片。对于那些对GC停顿时间敏感的应用,如实时系统和大数据处理系统,G1是一个非常合适的选择。
ZGC(Java 15)
ZGC 是一个可伸缩、低延迟的垃圾收集器,使用-XX:+UseZGC 命令开启。
名称中的“Z”并没有特定的含义,主要是一个名称,灵感来源于Oracle的ZFS文件系统。ZFS在设计上具有革命性,因此ZGC的命名也向其致敬。
在Java15发布时,提供的是不分代收集器,所有对象都放在一起,期望STW最大10ms。
在Java21的时候,基于「大部分对象朝生夕死」的分代假说,ZGC提供了分代版本,将内存划分为年轻代和老年代,并为这两种代分别维护不同的垃圾收集策略,期望STW最大是1ms。
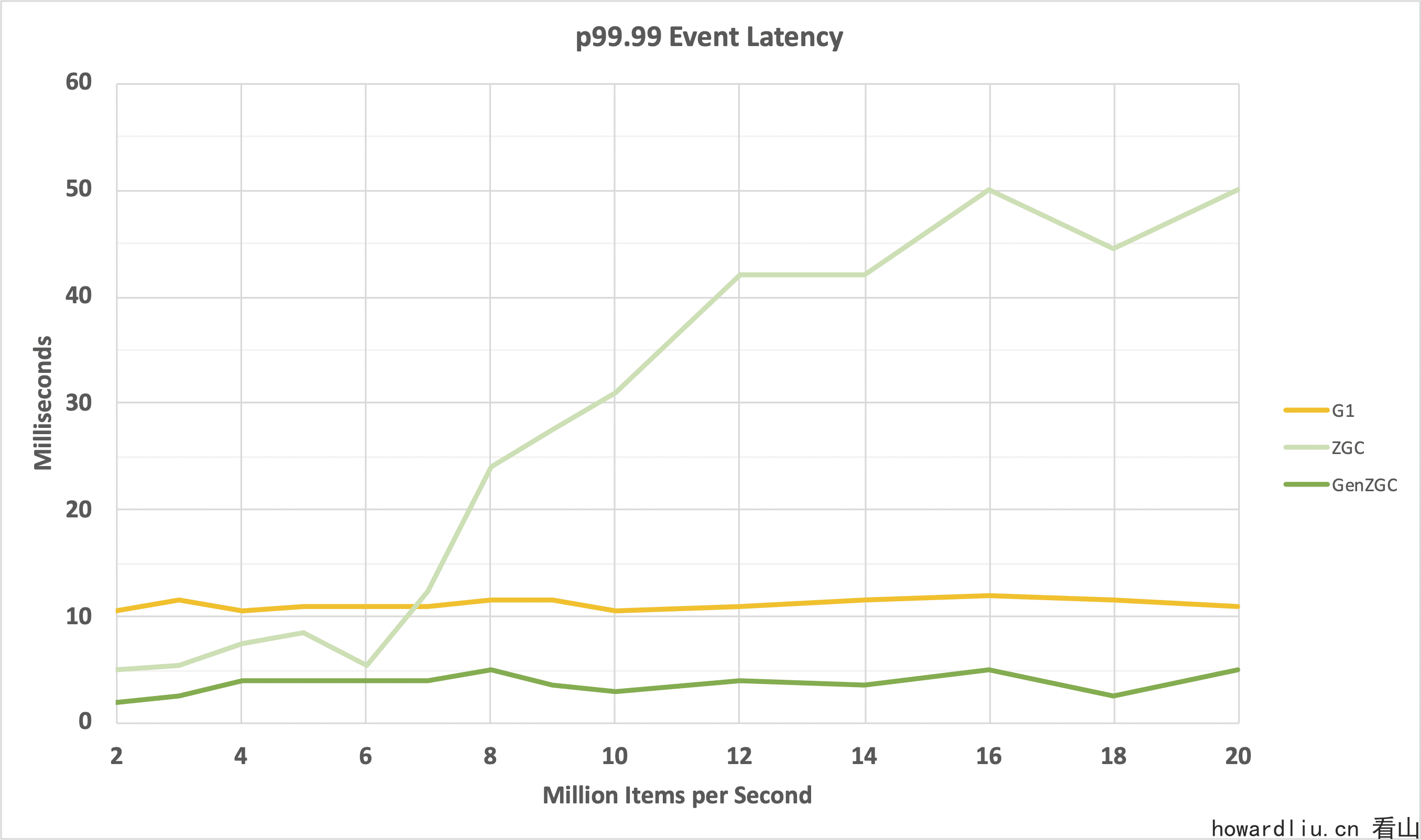
我们看下Hazelcast Jet on Generational ZGC中给出的测评效果:
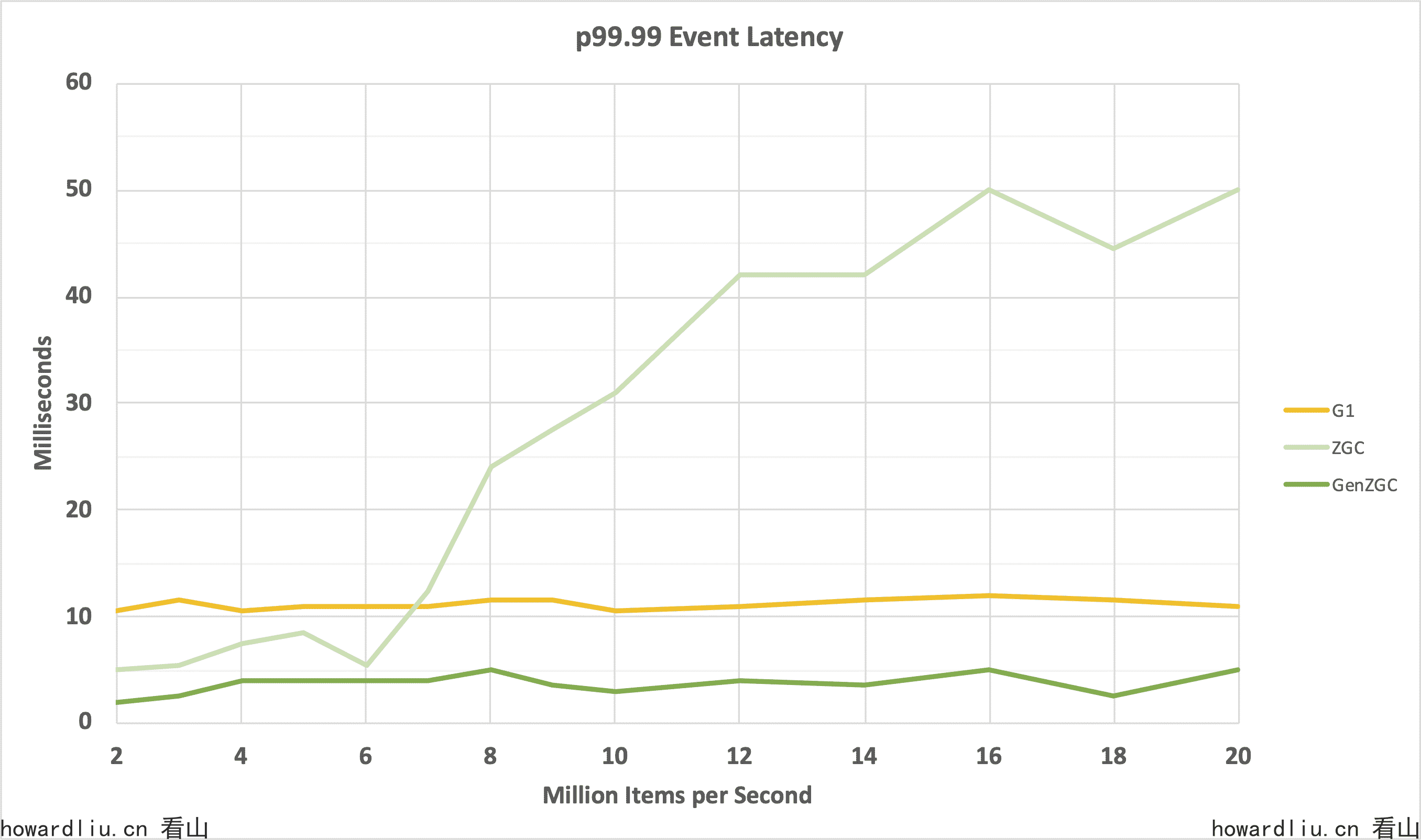
从上图可以看到,非分代 ZGC 在低负载下表现非常好,但随着分配压力的增加,延迟也会增加。使用分代 ZGC 后,即使在高负载下,延迟也非常低,而且延迟效果优于G1。
Shenandoah(Java 15)
Shenandoah(读音:谢南多厄),作为一个低停顿的垃圾收集器。
Shenandoah 垃圾收集器是 RedHat 在 2014 年宣布进行的垃圾收集器研究项目,其工作原理是通过与 Java 应用执行线程同时运行来降低停顿时间。
简单的说就是,Shenandoah 工作时与应用程序线程并发,通过交换 CPU 并发周期和空间以改善停顿时间,使得垃圾回收器执行线程能够在 Java 线程运行时进行堆压缩,并且标记和整理能够同时进行,因此避免了在大多数 JVM 垃圾收集器中所遇到的问题。
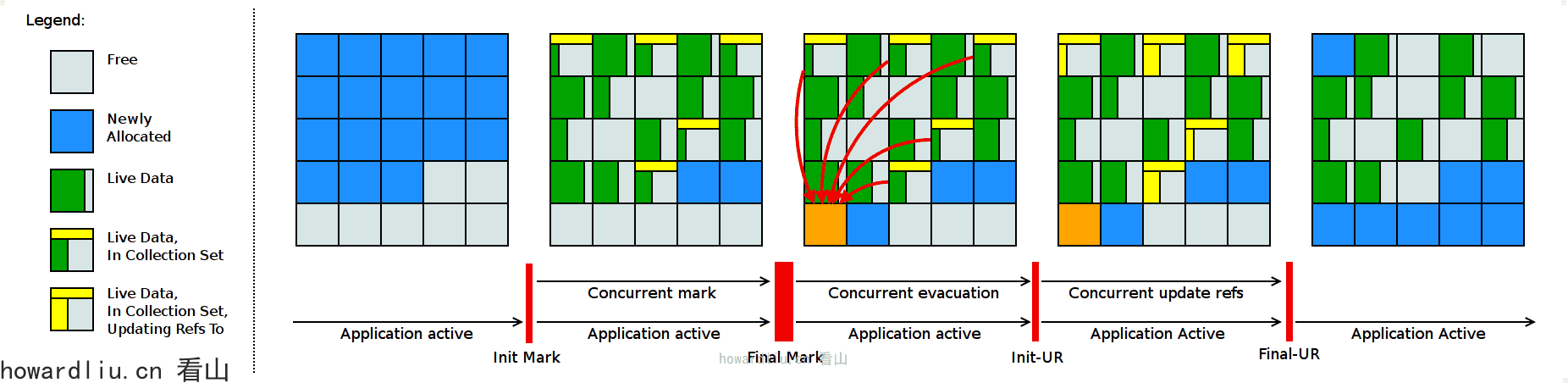
Shenandoah 垃圾回收器的暂停时间与堆大小无关,这意味着无论将堆设置为 200MB 还是 200GB,都将拥有一致的系统暂停时间,不过实际使用性能将取决于实际工作堆的大小和工作负载。
https://wiki.openjdk.java.net/display/shenandoah
一些小特性
增强 String
String中新增的方法:repeat、strip、stripLeading、stripTrailing、isBlank、lines、indent 和 transform。
这些方法还是挺有用的,以前我们可能需要借助第三方类库(比如 Apache 出品的 commons-lang)中的工具类,现在可以直接使用嫡亲方法了。
repeat
repeat是实例方法,顾名思义,这个方法是返回给定字符串的重复值的,参数是int类型,传参的时候需要注意:
- 如果重复次数小于 0 会抛出IllegalArgumentException异常;
- 如果重复次数为 0 或者字符串本身是空字符串,将返回空字符串;
- 如果重复次数为 1 直接返回本身;
- 如果字符串重复指定次数后,长度超过Integer.MAX_VALUE
,会抛出OutOfMemoryError`错误。
用法很简单:
@Testvoid testRepeat() { String output = "foo ".repeat(2) + "bar"; assertEquals("foo foo bar", output);}
小而美的一个工具方法。
strip、stripLeading、stripTrailing
strip方法算是trim方法的增强版,trim方法可以删除字符串两侧的空白字符(空格、tab 键、换行符),但是对于Unicode的空白字符无能为力,strip补足这一短板。
用起来是这样的:
@Testvoid testTrip() { final String output = " hello \u2005".strip(); assertEquals("hello", output); final String trimOutput = " hello \u2005".trim(); assertEquals("hello \u2005", trimOutput);}
对比一下可以看到,trim方法的清理功能稍弱。
stripLeading和stripTrailing与strip类似,区别是一个清理头,一个清理尾。用法如下:
@Testvoid testTripLeading() { final String output = " hello \u2005".stripLeading(); assertEquals("hello \u2005", output);}@Testvoid testTripTrailing() { final String output = " hello \u2005".stripTrailing(); assertEquals(" hello", output);}
isBlank
这个方法是用于判断字符串是否都是空白字符,除了空格、tab 键、换行符,也包括Unicode的空白字符。
用法很简单:
@Testvoid testIsBlank() { assertTrue(" \u2005".isBlank());}
lines
最后这个方法是将字符串转化为字符串Stream类型,字符串分隔依据是换行符:\n、\r、\r\n,用法如下:
@Testvoid testLines() { final String multiline = "This isa multilinestring."; final String output = multiline.lines() .filter(Predicate.not(String::isBlank)) .collect(Collectors.joining(" ")); assertEquals("This is a multiline string.", output);}
indent
indent方法是对字符串每行(使用\r或\n分隔)数据缩进指定空白字符,参数是 int 类型。
如果参数大于 0,就缩进指定数量的空格;如果参数小于 0,就将左侧的空字符删除指定数量,即右移。
我们看下源码:
public String indent(int n) { if (isEmpty()) { return ""; } Stream<String> stream = lines(); if (n > 0) { final String spaces = " ".repeat(n); stream = stream.map(s -> spaces + s); } else if (n == Integer.MIN_VALUE) { stream = stream.map(s -> s.stripLeading()); } else if (n < 0) { stream = stream.map(s -> s.substring(Math.min(-n, s.indexOfNonWhitespace()))); } return stream.collect(Collectors.joining("", "", ""));}
indent最后会将多行数据通过Collectors.joining("\n", "", "\n")方法拼接,结果会有两点需要注意:
\r会被替换成\n;- 如果原字符串是多行数据,最后一行的结尾没有
\n,最后会补上一个\n,即多了一个空行。
我们看下测试代码:
@Testvoid testIndent() { final String text = " 你好,我是看山。 \u0020\u2005Java12 的 新特性。 欢迎三连+关注哟"; assertEquals(" 你好,我是看山。 \u0020\u2005Java12 的 新特性。 欢迎三连+关注哟、n", text.indent(4)); assertEquals(" 你好,我是看山。\u2005Java12 的 新特性。 欢迎三连+关注哟、n", text.indent(-2)); final String text2 = "山水有相逢"; assertEquals("山水有相逢", text2);}
我们再来看看transform方法,源码一目了然:
public <R> R transform(Function<? super String, ? extends R> f) { return f.apply(this);}
通过传入的Function对当前字符串进行转换,转换结果由Function决定。比如,我们要对字符串反转:
@Testvoid testTransform() { final String text = "看山是山"; final String reverseText = text.transform(s -> new StringBuilder(s).reverse().toString()); assertEquals("山是山看", reverseText);}
增强文件读写(Java 11)
本次更新在Files中增加了两个方法:readString和writeString。writeString作用是将指定字符串写入文件,readString作用是从文件中读出内容到字符串。是一个对Files工具类的增强,封装了对输出流、字节等内容的操作。
用法比较简单:
@Testvoid testReadWriteString() throws IOException { final Path tmpPath = Path.of("./"); final Path tempFile = Files.createTempFile(tmpPath, "demo", ".txt"); final Path filePath = Files.writeString(tempFile, "看山 howardliu.cn 公众号:看山的小屋"); assertEquals(tempFile, filePath); final String fileContent = Files.readString(filePath); assertEquals("看山 howardliu.cn 公众号:看山的小屋", fileContent); Files.deleteIfExists(filePath);}
readString和writeString还可以指定字符集,不指定默认使用StandardCharsets.UTF\_8字符集,可以应对大部分场景了。
增强函数 Predicate(Java 11)
这个也是方法增强,在以前,我们在Stream中的filter方法判断否的时候,一般需要!运算,比如我们想要找到字符串列表中的数字,可以这样写:
final List<String> list = Arrays.asList("1", "a");final List<String> nums = list.stream() .filter(NumberUtils::isDigits) .collect(Collectors.toList());Assertions.assertEquals(1, nums.size());Assertions.assertTrue(nums.contains("1"));
想要找到非数字的,filter方法写的就会用到!非操作:
final List<String> notNums = list.stream() .filter(x -> !NumberUtils.isDigits(x)) .collect(Collectors.toList());Assertions.assertEquals(1, notNums.size());Assertions.assertTrue(notNums.contains("a"));
Predicate增加not方法,可以更加简单的实现非操作:
final List<String> notNums2 = list.stream() .filter(Predicate.not(NumberUtils::isDigits)) .collect(Collectors.toList());Assertions.assertEquals(1, notNums2.size());Assertions.assertTrue(notNums2.contains("a"));
有些教程还会推崇静态引入,比如在头部使用import static java.util.function.Predicate.not,这样在函数式编程时,可以写更少的代码,语义更强,比如:
final List<String> notNums2 = list.stream() .filter(not(NumberUtils::isDigits)) .collect(toList());
未命名模式和变量(Java 22)
该特性使用下划线字符 \_ 来表示未命名的模式和变量,从而简化代码并提高代码可读性和可维护性。
比如:
public static void main(String[] args) { var _ = new Point(1, 2);}record Point(int x, int y) {}
这个可以用在任何定义变量的地方,比如:
... instanceof Point(\_, int y)r instanceof Point \_switch …… case Box(\_)for (Order \_ : orders)for (int i = 0, \_ = sideEffect(); i < 10; i++)try { ... } catch (Exception \_) { ... } catch (Throwable \_) { ... }
只要是这个不准备用,可以一律使用\_代替。
Markdown格式文档注释(Java 23)
Markdown是一种轻量级的标记语言,可用于在纯文本文档中添加格式化元素,具体语法可以参考Markdown Guide。本文就是使用Markdown语法编写的。
在Java注释中引入Markdown,目标是使API文档注释以源代码形式更易于编写和阅读。主要收益包括:
- 提高文档编写的效率:Markdown语法相比HTML更为简洁,开发者可以更快地编写和修改文档注释。
- 增强文档的可读性:Markdown格式的文档在源代码中更易于阅读,有助于开发者快速理解API的用途和行为。
- 促进文档的一致性:通过支持Markdown,可以确保文档风格的一致性,减少因格式问题导致的文档混乱。
- 简化文档维护:Markdown格式的文档注释更易于维护和更新,特别是在多人协作的项目中,可以减少因文档格式问题导致的沟通成本。
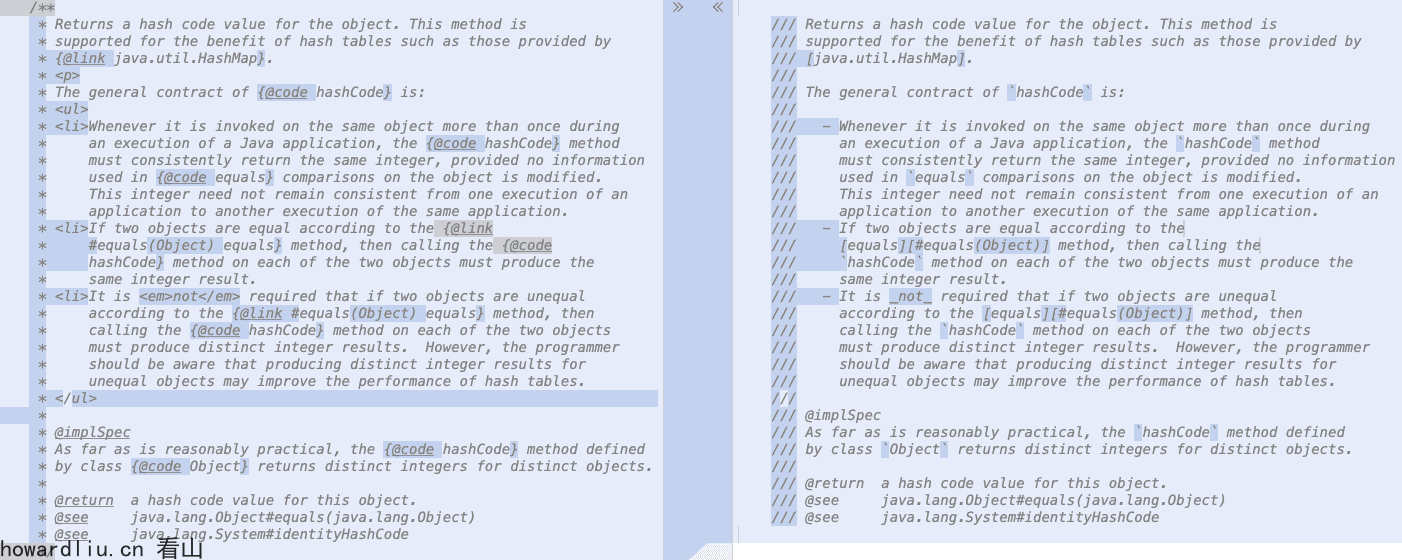
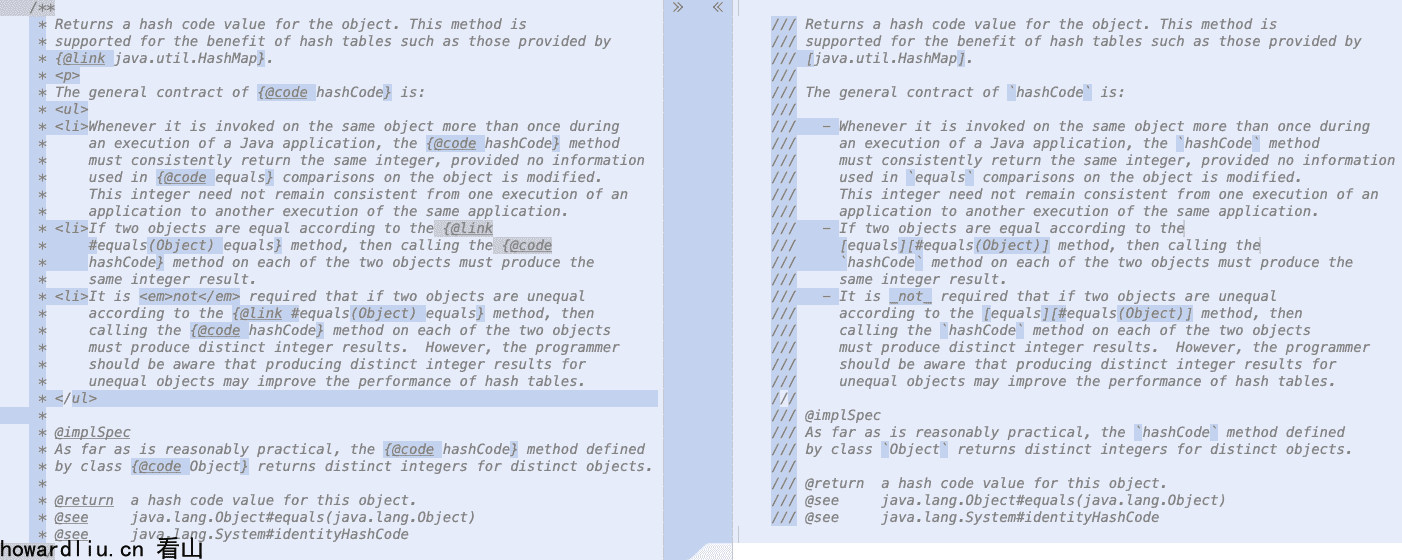
具体使用方式是在注释前面增加///,比如java.lang.Object.hashCode的注释:
/** * Returns a hash code value for the object. This method is * supported for the benefit of hash tables such as those provided by * {@link java.util.HashMap}. * <p> * The general contract of {@code hashCode} is: * <ul> * <li>Whenever it is invoked on the same object more than once during * an execution of a Java application, the {@code hashCode} method * must consistently return the same integer, provided no information * used in {@code equals} comparisons on the object is modified. * This integer need not remain consistent from one execution of an * application to another execution of the same application. * <li>If two objects are equal according to the {@link * #equals(Object) equals} method, then calling the {@code * hashCode} method on each of the two objects must produce the * same integer result. * <li>It is <em>not</em> required that if two objects are unequal * according to the {@link #equals(Object) equals} method, then * calling the {@code hashCode} method on each of the two objects * must produce distinct integer results. However, the programmer * should be aware that producing distinct integer results for * unequal objects may improve the performance of hash tables. * </ul> * * @implSpec * As far as is reasonably practical, the {@code hashCode} method defined * by class {@code Object} returns distinct integers for distinct objects. * * @return a hash code value for this object. * @see java.lang.Object#equals(java.lang.Object) * @see java.lang.System#identityHashCode */
如果使用JEP 467的Markdown方式:
/// Returns a hash code value for the object. This method is/// supported for the benefit of hash tables such as those provided by/// [java.util.HashMap].////// The general contract of `hashCode` is:////// - Whenever it is invoked on the same object more than once during/// an execution of a Java application, the `hashCode` method/// must consistently return the same integer, provided no information/// used in `equals` comparisons on the object is modified./// This integer need not remain consistent from one execution of an/// application to another execution of the same application./// - If two objects are equal according to the/// [equals][#equals(Object)] method, then calling the/// `hashCode` method on each of the two objects must produce the/// same integer result./// - It is _not_ required that if two objects are unequal/// according to the [equals][#equals(Object)] method, then/// calling the `hashCode` method on each of the two objects/// must produce distinct integer results. However, the programmer/// should be aware that producing distinct integer results for/// unequal objects may improve the performance of hash tables.////// @implSpec/// As far as is reasonably practical, the `hashCode` method defined/// by class `Object` returns distinct integers for distinct objects.////// @return a hash code value for this object./// @see java.lang.Object#equals(java.lang.Object)/// @see java.lang.System#identityHashCode
简单两种写法的差异,相同注释,Markdown的写法更加简洁:
一些可能不会用到的特性
web服务器jwebserver(Java 18)
为开发者提供一个轻量级、简单易用的 HTTP 服务器,通过命令行工具jwebserver可以启动一个最小化的静态 Web 服务器,这个服务器仅支持静态资源的访问,不支持 CGI(Common Gateway Interface)或类似 servlet 的功能,主要用于原型制作、测试和开发环境中的静态文件托管与共享。
它的应用场景包括:
- 原型开发:由于其简单易用的特性,jwebserver 可以作为快速原型开发工具,帮助开发者在短时间内搭建起一个可以访问静态资源的 Web 服务。这对于需要验证某个功能或概念的初期阶段非常有用。
- 快速部署:对于一些小规模的应用或者临时性的项目,使用 jwebserver 可以快速启动并运行一个简单的 Web 服务,而无需复杂的配置和环境搭建。这使得开发者能够迅速将想法转化为实际的可访问服务。
- 学习与教育:jwebserver 提供了一个直观的平台,让初学者可以轻松上手 Java Web 开发。通过简单的命令行操作,用户可以快速理解 Web 服务器的工作原理及其基本配置。
- 测试与调试:在进行 Web 应用的测试和调试时,jwebserver 可以作为一个独立的工具来提供静态文件的访问服务,从而方便开发者对应用进行测试和调试。
- 本地开发环境:在本地开发环境中,jwebserver 可以替代传统的 Web 服务器如 Apache Tomcat 或 Nginx,为开发者提供一个轻量级的选择,以减少系统资源的占用。
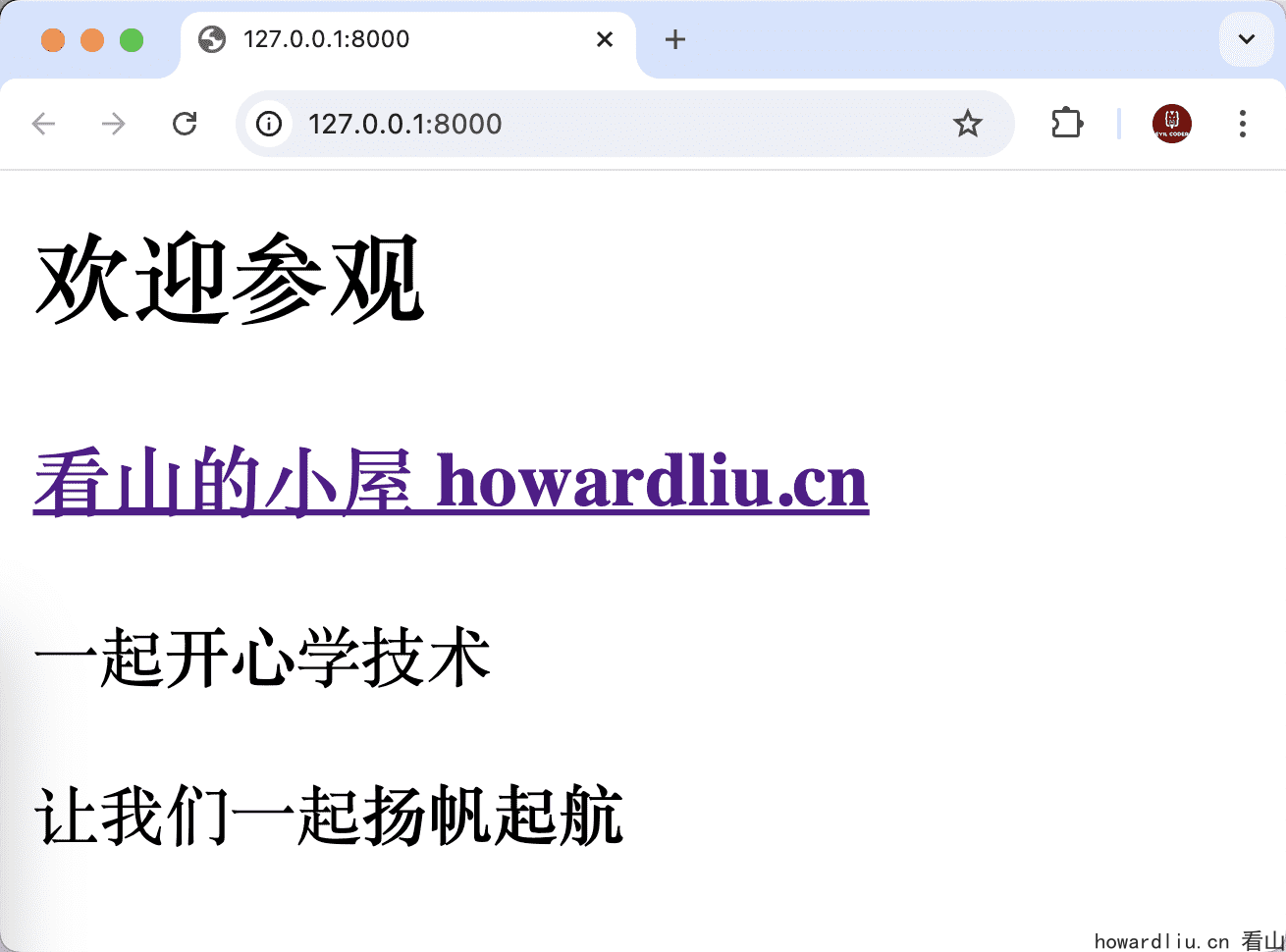
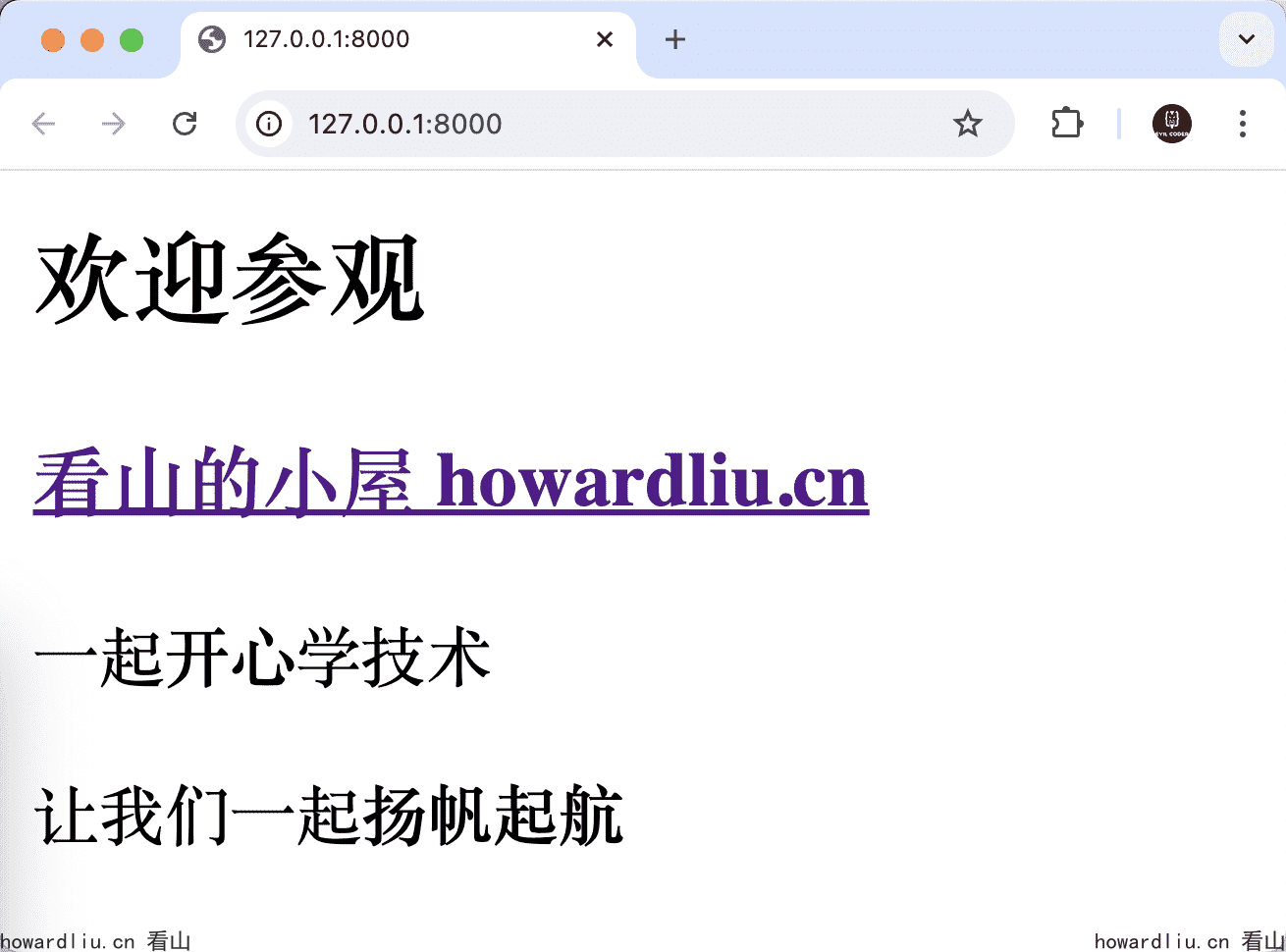
我们可以简单试一下,在当前目录编写index.html:
<html><head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /></head><body> <h2>欢迎参观</h2> <h3><a href="https://www.howardliu.cn/">看山的小屋 howardliu.cn</a></h3> <p> 一起<strong>开心</strong>学技术 </p> <p> 让我们一起<strong>扬帆起航</strong> </p></body></html>
运行jwebserver命令:
$ ./bin/jwebserverBinding to loopback by default. For all interfaces use "-b 0.0.0.0" or "-b ::".Serving /Users/liuxinghao/Library/Java/JavaVirtualMachines/temurin-18.0.2.1/Contents/Home and subdirectories on 127.0.0.1 port 8000URL http://127.0.0.1:8000/
打开[http://127.0.0.1:8000/](http://127.0.0.1:8000/)就可以直接看到index.html的效果:
jwebserver还支持指定地址和端口等参数,具体使用可以通过命令查看:
$ ./bin/jwebserver -hUsage: jwebserver [-b bind address] [-p port] [-d directory] [-o none|info|verbose] [-h to show options] [-version to show version information]Options:-b, --bind-address - Address to bind to. Default: 127.0.0.1 (loopback). For all interfaces use "-b 0.0.0.0" or "-b ::".-d, --directory - Directory to serve. Default: current directory.-o, --output - Output format. none|info|verbose. Default: info.-p, --port - Port to listen on. Default: 8000.-h, -?, --help - Prints this help message and exits.-version, --version - Prints version information and exits.
隐式声明的类和实例方法(预览特性)
隐式声明的类和实例方法的目标是简化 Java 语言,使得学生和初学者可以更容易地编写他们的第一个程序,而无需理解为大型程序设计的复杂语言特性。
无论学习哪门语言,第一课一定是打印Hello, World!,Java中的写法是:
public class HelloWorld { public static void main(String[] args) { System.out.println ("Hello, World!"); }}
如果是第一次接触,一定会有很多疑问,public干啥的,main方法的约定参数args是什么鬼?然后老师就说,这就是模板,照着抄就行,不这样写不运行。
现在可以简化为:
class HelloWorld { void main() { System.out.println ("Hello, World!"); }}
我们还可以这样写:
String greeting() { return "Hello, World!"; }void main() { System.out.println(greeting());}
main方法直接简化为名字和括号,甚至连类也不需要显性定义了。虽然看起来没啥用,但是在JShell中使用,就比较友好了。
本次预览新增了三个IO操作方法:
public static void println(Object obj);public static void print(Object obj);public static String readln(String prompt);
想要快速实现控制台操作,可以这样写了:
void main() { String name = readln("请输入姓名: "); print("很高兴见到你, "); println(name);}
作为一个老程序猿,也不得不哇塞一下。
文末总结
想要了解各版本的详细特性,可以从从小工到专家的 Java 进阶之旅 系列专栏中查看。
青山不改,绿水长流,我们下次见。
推荐阅读
你好,我是看山。游于码界,戏享人生。如果文章对您有帮助,请点赞、收藏、关注。我还整理了一些精品学习资料,关注公众号「看山的小屋」,回复“资料”即可获得。
👇🏻欢迎关注我的公众号「看山的小屋」,领取精选资料👇🏻
]]>