
你好,我是看山。
在一些系统中,会有对某些任务状态进行跟踪,如果任务失败需要重新执行任务。本文主要是针对这种请求提出解决方案,因为时间原因,方案还没有在代码中实现。但是经过和 朋友 的推演,是目前能想到的比较有效的方案了。鉴于本人才疏学浅,如果有某位大神有更好的解决方案,请一定不吝赐教,感谢不尽。
1. 问题描述
1.1 一个主任务,多个子任务
在当前的系统环境中,通常一个应用会有多个实例,即水平拆分,提升并发能力。正常情况下,一个实例接收到一条请求,即开始对该请求进行处理。如果该请求是命令当前实例对某一分类下所有商品重建索引,假设该分类下有 10000 个商品,即该实例在接下来一段时间要有大量资源投入到重建索引中。但是其他实例都在闲着,形成一人干活,众人围观的局面。
假如该任务正常结束,这种方式也是没什么太大的问题的。但是可能出现一种极端的情况,该实例对其中的 9999 件商品重建索引都成功了,恰巧重建最后一条时失败实例挂了,则当前任务即任务是失败的,那前面的 9999 件商品创建索引的工作就是白费的。
1.2 任务状态跟踪
在一个消息平台中,接收到的消息向目标地址发送失败后,在一段时间后需要再尝试发送几次,保证消息可达。如果经过几次重试之后,发送消息依然失败,那将消息状态置为失败,等待人工干预。
假设这个消息平台很不靠谱,或者目标服务不靠谱,经过一段时间后,重试任务累计到 3000。这 3000 条需要重试的任务不均匀的分布的各个时间段上,消息标识不是序列号,没法通过序列号段进行取数。在这种情况下,即使有个多个实例可以同时对这些消息重试,为了不遗漏、不重复,只能够简单的通过时间分组重试,这样就会有任务分配不均,无法很好发挥集群的问题处理协作能力。
2. 解题思路
其实上面两种情况可以认为是一种,即一堆无状态的任务需要被执行。为了资源的有效利用,不应该同时有多个应用执行任务,而且当任务成功后,也不需要再次执行。
最直接和最简单的思路就是需要提供可存储任务的系统:
- 定时的或以监听的方式从该存储系统中获取任务列表
- 检查该任务是否被加锁,如果加锁,放弃执行该任务;如果未加锁,对该任务加锁
- 开始执行任务
- 执行结束后,将任务结果写入存储系统,并对任务解锁
- 重复 1 操作,如果发现任务成功执行,则跳过任务或归档任务
3. 解决方案
3.1 轮询
根据上面的解题思路,定时轮询是最简单最直接的方案。
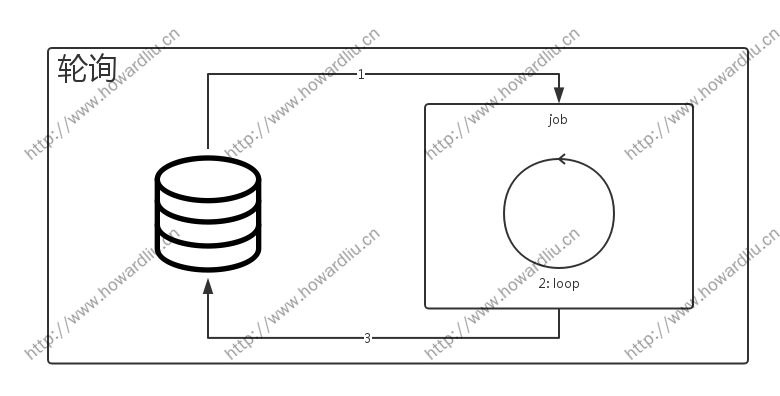
如上图所示:
- JOB 任务定时从 1 中获取任务列表
- 循环操作任务列表中的任务
- 将任务结果写回数据库
但是这种方式可优化的地方很多,比如:
- 如果有多个实例,每个实例在任务启动的时候取任务列表中的一部分,即分页取任务列表。这就需要保证任务列表可有效分页,并且需要保证任务平均分散在任务列表每页中。比如根据时间取列表,而且任务列表在时间轴上比较均匀。
- 同一个任务执行过程中要有锁,不需要两个实例同时执行同一个任务
- 任务执行过程中要有状态。当该任务执行还没有成功完成时,如果持有该任务的实例死亡,能够有其他实例重新执行该任务
这种方式是我接手代码中使用的方式,但是那个人没有对任务列表分页。正常情况下,任务列表很短,只有小于 100 条,而且获取任务列表周期是 5 分钟,运行完全没有问题。但是一旦任务集中输入的时候,每次都获取所有任务,可以想象,一个实例在某一时刻输入 3000 个任务,然后开始一个一个执行,任务执行时间无限延长。为了利用集群共同处理问题的能力,于是开始对代码进行改造,就是下面这种轮询+监听的方式。
3.2 轮询+监听
轮询+监听的方式也是有弊端的,后面慢慢说。
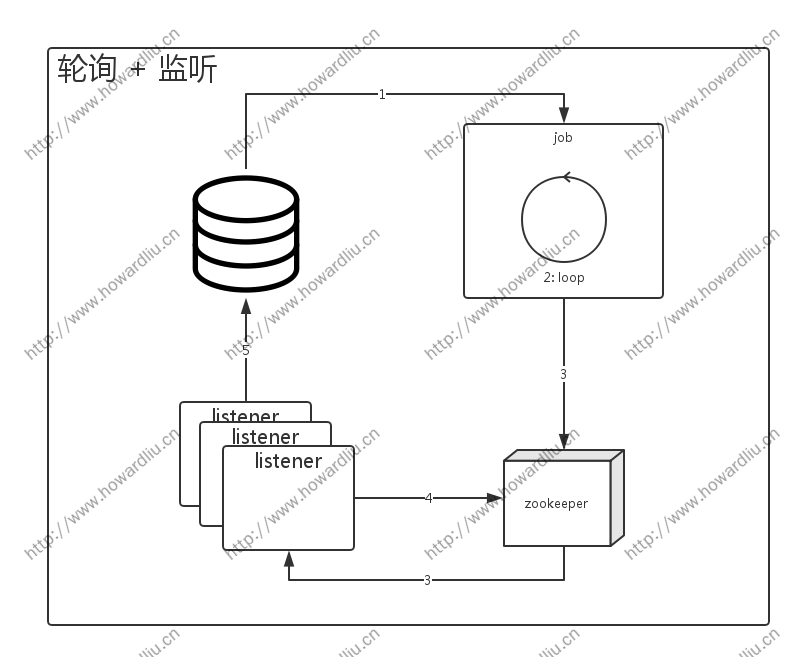
如上图,很明显的可以看出,这个能够算是 3.1 的升级版(虽然是升级版,效果依然不佳)。
- JOB 任务定时从数据获取任务列表
- 循环操作任务列表,剔除不符合要求的任务
- 将符合要求的任务写入 zookeeper,在 taskPath 下创建任务节点。
- Listener 监听 taskPath 字节点事件,发现有任务节点创建事件,从 zookeeper 读取节点数据,开始执行任务
- 任务执行结束,将任务状态写回数据库
这种方式增强了任务执行效率,只要 JOB 定时规则设置合理,理论上任务会随机分配到各个监听实例中,并执行任务。这个方案中的短板在定时轮询和 zookeeper 压力:
- 定时轮询:因为时间紧,所以没有抛弃一开始 JOB 轮询任务这部分。所以只能够利用 zookeeper 的分布式锁,集群中某一实例读取读取任务列表,并将任务写入 zookeeper。如果没有后面的问题,也是可以接受这种方式。
- zookeeper 服务压力:因为 zookeeper 的节点监听是要创建长连接、而且经常要向 zookeeper 方法状态确认请求,所以如果任务节点比较多、且驻留时间较长的时候,对 zookeeper 服务器压力比较大。有弊必有利,如果服务器能够撑住这种压力,这种方式能够保证,任务节点的任何变化,能够被准实时的感知到,针对任务变化,迅速做出响应。
3.3 任务队列
分析前面两种方案的短板,以及加上之前的经验。其实解决方案就呼之欲出了:一个很长的任务列表,最快的方法是分组批量执行,即分页获取列表中任务,然后使用多线程批量执行这些任务。(至于每次取多少,使用多少线程执行只能根据不同的任务难度、任务周期来计算了):
- 分页获取:分页的难度就在于分页要均匀,且有明显的分页标识,以便另外一个实例不会重复获取已经分页数据。最简单的数据结构就是 FIFO 队列,能够顺序读取队列中的数据。因为是集群环境,只需要这个队列能够实现数据排他(删除、隐藏或通过位移控制)读取即可。
- 批量执行:批量执行最简单的方式是通过多线程并行执行任务,这点不难。
执行过程如下图所示:

- producer 将任务数据写入数据库,做备份或记录任务状态使用
- producer 将任务数据写入任务队列中
- consumer 从任务队列中分页获取任务列表,批量执行。根据执行情况及执行状态,判断是否重新返回任务队列等待执行
- 执行成功的任务,将任务状态入库
- 执行失败的任务重新写回任务队列,等待再次被读取执行
这里需要考虑一种异常情况:如果某一实例的 consumer 读取任务列表,任务队列将已读取任务列表删除后,该实例死亡。在该方案中,将丢失该实例中的任务,下面的双任务队列的方式可以解决这个问题。
3.4 双任务队列
可以考虑这个一个例子,生产线上工人们在做工,从传送带上取一组零件进行检查。检查不合格重新放会生产线末尾,等待机器重新加工零件;检查合格装箱打包。传送带即任务队列;员工即 consumer;员工取一组零件后传送带上就没有这些零件,即任务被排他获取;零件合格装箱,即任务成功;零件不合格重新放回传送带,即任务失败。与上面的方案很类似。
假设,有一个员工取完零件并检查了一半了,有的装箱,有的打回,然后突然不想干了,直接走了。这个时候其工作台上就散落一堆未检查零件。如果有一个人巡逻检查各个工作台,发现无人职守且有散落零件的工作台,只要把工作台上的零件放回传送带,这些零件又能够被正常的检查。
将上面的例子应用到我们的方案中,就是一个双任务队列的模型,如下图所示:

- producer 将任务数据写入数据库,做备份或记录任务状态使用
- producer 将任务数据写入任务队列中
- consumer 从任务队列中分页获取任务列表
- consumer 将任务列表写入第二任务队列,防止任务丢失
- 执行成功的任务,将任务状态入库
- 执行失败的任务重新写回任务队列,等待再次被读取执行
- 定时任务检查任务第二任务队列,找到无主任务
- 定时任务将从第二任务队列中获取的无主任务写回 producer
考虑这种情况:如果任务队列排他读取方式中使用的是数据读取后删除,那么 consumer 在读取数据之后,写入第二任务队列之前,所在实例死亡,任务依然会丢失。所以比较稳妥的办法是,任务队列的排他方式是屏蔽或位移。
- 屏蔽,就是如果有一个 consumer 读取任务数据,则将改任务数据状态修改,其他 consumer 不能够再看到该条数据,等待 consumer 确认之后,则可以将数据删除或归档。
- 位移是通过一个位移量记录当前读取位置,并设置锁,其他 consumer 等待当前处理任务,处理结束后,提交位移量,其他 consumer 可以读取数据。
4 任务队列的选择
4.1 RabbitMQ
在 RabbitMQ 中,可以通过监听的方式Channel.basicConsume获取队列中的任务消息,为了安全考虑,需要将第二个参数autoAck置为 false。这样当前的 consumer 读取消息之后,消息状态是 Unacked,这个时候其他 consumer 就不能够看到这条消息,只有主动调用Channel.basicAck确认之后,消息才会被删除。如果消息未被 ack 确认,当前 consumer 死亡,消息会被重新置为 Ready 状态,可以被其他 consumer 消费。这种即上面所说的屏蔽的方式,任务可以无序的执行。
为了可以尽可能的榨干集群中每个实例的资源,每个实例可以启用多个线程同时监听队列,即每个实例有多个 consumer,这样能够尽可能快的将消息出队。下面是简单的实例代码,先创建指向 RabbitMQ 集群的连接,然后通过 producer 向 RabbitMQ 服务发送数据,最后通过 consumer 订阅方式消费消息。
创建连接:
ConnectionFactory factory = new ConnectionFactory();
factory.setVirtualHost("/");
factory.setUsername("username");
factory.setPassword("password");
factory.setAutomaticRecoveryEnabled(true);
factory.setNetworkRecoveryInterval(10000);
factory.setConnectionTimeout(60);
Address[] addressArray = new Address[]{new Address("127.0.0.1", 5672)};
ExecutorService es = Executors.newFixedThreadPool(200, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
thread.setName("rabbitMQ-thread-" + thread.getId());
return thread;
}
});
Connection conn = factory.newConnection(es, addressArray);简单的 producer:
Channel channel = conn.createChannel();
channel.basicPublish("someExChange", "someQueue", true, MessageProperties.PERSISTENT_TEXT_PLAIN, "Hello, world!".getBytes());每个线程中 consumer 可以如下面的实例代码:
final Thread currentThread = Thread.currentThread();
try {
final Channel channel = conn.createChannel();
channel.basicConsume("someQueue", false, "someConsumerTag",
new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
String routingKey = envelope.getRoutingKey();
String contentType = properties.getContentType();
long deliveryTag = envelope.getDeliveryTag();
String message = new String(body, "UTF-8");
logger.info("threadName={}, routingKey={}, contentType={}, deliveryTag={}, message={}",
currentThread.getName(), routingKey, contentType, deliveryTag, message);
// 任务处理开始
// ...
// 任务处理结束
channel.basicAck(deliveryTag, false);
}
});
} catch (IOException e) {
logger.error("发生错误", e);
}4.2 Kafka
Kafka 的设计是用于顺序存储日志,通过这种设计,可以变相的用于有序队列,这种有序队列可以用于有序任务。定义一个有 20 个 Partition 的 Topic,在集群中的每个实例中,启动 5 个线程作为 consumer 读取。(为了有效利用资源,Partition 的数量要大于等于 consumer 线程数,这样不会导致有些线程空闲,白白耗费资源)。
为了保证某一实例死亡后,其他实例可以继续上个实例未完成的任务,需要在每个任务消息处理结束后,调用ConsumerConnector.commitOffsets(true)来修改偏移量。这种即上面说的位移的方式。
在 kafka 中有一种可变的使用方式,可以是任务有序或无序:
- 有序:通过 producer 向 kafka 写数据的时候,设置一个 key(kafka 通过对 key 做 hash,将数据写入对应 partition 中),如果设置的 key 固定,则 partition 固定,读取的 consumer 即相对固定(说相对是因为 consumer 会隔一段时间做负载均衡,所以可能会切换 consumer)。在这种方式中,任务是有序执行的。缺点就是,集群中只会有一个实例能够获得读取数据的权利,其他实例都在等待。只有当这个实例死亡,才会有其他实例获得权利,继续上个实例未尽的事业。
- 无序:在通过 producer 写数据的时候,可以将 key 中加一个变化的值,使数据均匀的分布在不同的 partition 中,这样不同的实例的 consumer 就都可以读取数据了。
producer 代码实例(示例代码为有序方式,无序方式只需要根据实际情况修改 job-key 即可):
import static org.apache.kafka.clients.producer.ProducerConfig.*;
Properties properties = new Properties();
properties.put(BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
properties.put(ACKS_CONFIG, "all");// 0, 1, all
properties.put(BUFFER_MEMORY_CONFIG, "33554432");
properties.put(COMPRESSION_TYPE_CONFIG, "none");// none, gzip, snappy
properties.put(RETRIES_CONFIG, "0");
properties.put(BATCH_SIZE_CONFIG, "16384");
properties.put(CLIENT_ID_CONFIG, "someClientId");
properties.put(LINGER_MS_CONFIG, "0");
properties.put(MAX_REQUEST_SIZE_CONFIG, "1048576");
properties.put(RECEIVE_BUFFER_CONFIG, "32768");
properties.put(SEND_BUFFER_CONFIG, "131072");
properties.put(TIMEOUT_CONFIG, "30000");
properties.put(KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
ProducerRecord<String, String> topic = new ProducerRecord<>("mq-job-topic", "job-key", "{id:1}");
kafkaProducer.send(topic, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
logger.info("topic={}, partition={}, offset={}", metadata.topic(), metadata.partition(), metadata.offset());
} else {
logger.error("producer 发送消息失败", exception);
}
}
});
kafkaProducer.close();consumer 代码实例:
Properties properties = new Properties();
properties.put("zookeeper.connect", "127.0.0.1:2181/kafka");
properties.put("fetch.message.max.bytes", "1048576");
properties.put("group.id", "someGroupId");
properties.put("auto.commit.enable", "false");
properties.put("auto.offset.reset", "largest");// smallest, largest
final ConsumerConnector connector = new KafkaConsumerFactory(properties).build();
Map<String, Integer> topicCountMap = new HashMap<>();
topicCountMap.put("mq-job-topic", 10);
Map<String, List<KafkaStream<byte[], byte[]>>> messageStreams = connector.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> kafkaStreams = messageStreams.get("mq-job-topic");
ExecutorService executorService = Executors.newFixedThreadPool(10, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
return t;
}
});
for (final KafkaStream<byte[], byte[]> kafkaStream : kafkaStreams) {
executorService.submit(new Runnable() {
@Override
public void run() {
for (MessageAndMetadata<byte[], byte[]> messageAndMetadata : kafkaStream) {
try {
String key = new String(messageAndMetadata.key(), "UTF-8");
String message = new String(messageAndMetadata.message(), "UTF-8");
logger.info("message={}, key={}", message, key);
// 任务处理开始
// ...
// 任务处理结束
connector.commitOffsets(true);
} catch (Exception e) {
logger.error("发生异常", e);
}
}
}
}, null);
}5 写在最后
虽然没有在项目中确实的使用这种解决方案,但是已经通过 demo 进行了技术验证。另外,分布式队列可以根据不同的需求选择 RabbitMQ(任务无序)或 Kafka(任务有序、无序),当然绝不限于这两种,还可以有很多其他的选择。
你好,我是看山,公众号:看山的小屋,10 年老猿,开源贡献者。游于码界,戏享人生。关注我,领取资料。
个人主页:https://www.howardliu.cn
个人博文:解决方案之任务队列
CSDN 主页:http://blog.csdn.net/liuxinghao
CSDN 博文:解决方案之任务队列
