前段时间搭建了一套Hadoop集群的测试环境,因为服务器故障,废了。这几天闲来无事,想着把Storm用Yarn管理起来,于是再来一遍,同时也梳理下Hadoop组件中的一些概念。所谓书读百遍其义自见,不熟的系统多搭几遍,总会熟悉了,也就是所谓的刻意练习吧。
先简单的说下。
Hadoop文件存储的基础是HDFS(Hadoop Distributed File System),HDFS的实现依赖于NameNode和DataNode,DataNode用来存储具体数据,NameNode用来管理多个DataNode中分别存储的是什么。
理解起来也不难,因为HDFS是分布式的文件系统,也就是有很多机器用来存储数据,一个大文件可能分布在多个机器上,也可能是一台机器上,具体分布在哪些或哪个机器上,每块数据块的副本在哪,得需要一个总管来管理,这个总管就是NameNode,具体存储机器的就是DataNode。
简单的说完了,接下来就复杂的说。
1. HDFS架构
HDFS是主/从架构,一个HDFS只有一个NameNode(这里的一个是指起作用的只有一个,在NameNode的HA状态下,也是只有一个NameNode起作用,其他的NameNode节点只是备份,家有千口,主事一人嘛)。这个NameNode管理整个文件系统的命名空间(The File System Namespace),并且调节客户端对文件的访问。DataNode用来存储数据,还有一些DataNode用来管理连接到运行节点的存储。HDFS公开文件系统的命名空间,允许用户在文件系统中存储数据。
在HDFS内部,一个文件被分割为一个或多个数据块,这些数据块存储在一组DataNode上。NameNode负责文件系统的命名空间操作,比如对文件或文件夹执行打开、关闭,以及重命名操作,同时,也负责将数据块映射到DataNode上。DataNode负责向客户端提供对文件系统的读取和写入请求的处理。DataNode还能根据NameNode的指示,执行数据块的创建、删除和复制操作。
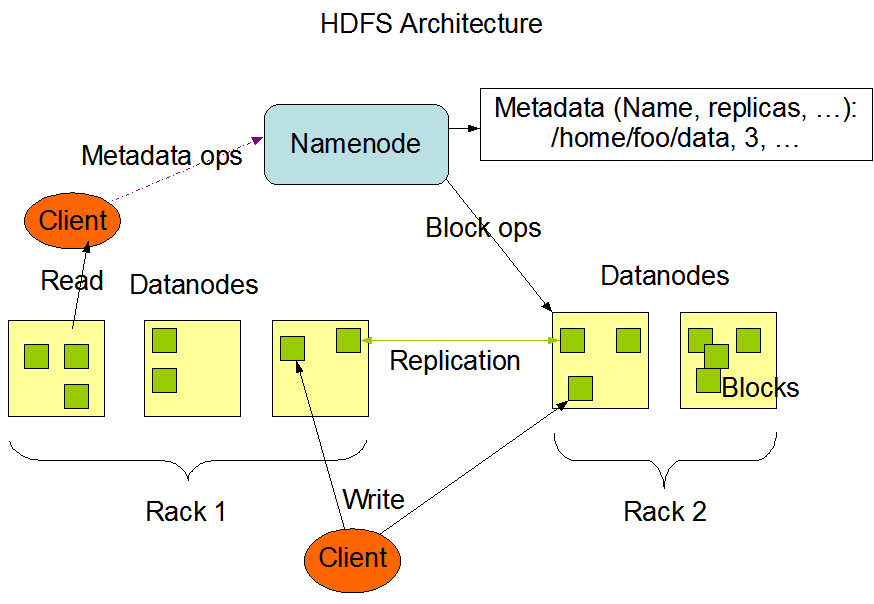
NameNode和DataNode通常运行在普通商用服务器上(这里是针对小型机这种又贵很又特别贵的机器说的),这些机器一般装的是Linux。HDFS使用Java实现的,而且Java号称是一处编译到处运行,也就是只要有Java环境,就能运行NameNode和DataNode。典型的部署方式是,一台机器运行NameNode,其他机器运行DataNode,每台机器一个进程。(当然也可能一台机器上有多个DataNode,但是生产环境应该不会有这种情况,毕竟没有任何好处)
HDFS的这种主从架构保证了,所有的数据都会从NameNode经过,这样也简化了系统的体系结构,NameNode就是老大,所有数据都经过他。当然老大也可能出现意外,就得需要其他HA的部署方式(找几个小弟时刻准备接替老大),这个后面再说。
2. 文件系统
HDFS文件系统设计与传统分层文件系统类似,有文件夹,文件夹里可以有文件夹或文件。客户端可以对这些文件夹或文件进行操作,比如创建、删除、移动、重命名等。不过目前还不支持软连接和硬连接,后面可能会支持。
如前面所说,这个命名空间由NameNode维护。所有的文件/文件夹的名字、属性、复制因子都由NameNode记录。
3. 数据复制
HDFS设计用于在大型集群中存储非常大的文件,它将每个文件存储为一组数据块块中,除了最后一块外,所有文件块大小相同(默认是64MB),HDFS通过复制数据块块进行容错,每个文件的数据块大小、复制因子都是可配的。客户端可以指定文件的副本数,可以在创建时指定,也可以在之后修改。HDFS中的文件是一次写入的,并且在任何时候都有一个明确的作者。
NameNode来管理所有数据块复制操作,它定期与集群中每个DataNode进行心跳和文件块报告。收到心跳意味着DataNode正常运行,文件块报告是DataNode上所有文件块的列表。
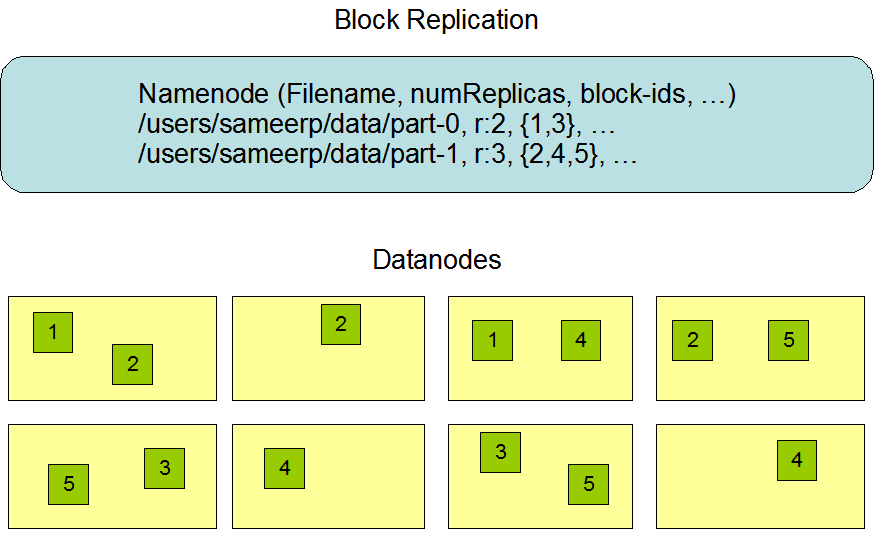
3.1 副本存储
副本存储的位置对于HDFS的可靠性和性能是至关重要的,优化副本存储是HDFS与大多数其他分布式文件系统区分开来的优点之一,这是一个经过大量调整和体验的功能。机架感知副本存储策略的目的是提高数据可靠性、可用性和网络带宽的高利用率。目前的副本存储策略是朝这个方向努力的第一步。实施这一政策的短期目标是对生产系统进行验证,更多的了解其行为,并为更加复杂的策略进行测试和研究奠定基础。
大型的HDFS实例通常运行在多个机架上,不同机架中的两个节点之间通信必须通过交换机。通产,同一机架上的机器之间的网络速率会优于不同机架间的速率。
NameNode通过Hadoop 机架感知中介绍的方式确定每个DataNode所属的机架ID。一个简单但不是最优策略是将副本存储在不同的机架上,这样可以防止整个机架故障导致数据丢失,并允许读取数据时使用多个机架的带宽。该策略保证可以在集群中均匀分配副本,可以轻松平衡组件故障时的负载。但是,这种策略会因为需要将副本数据写到多个机架,而增加写入成本。
常见情况中,复制因子是3,HDFS的副本存储策略是将一个副本放置在当前机架上的一个节点上,另一个位于另一个机架上的某个节点上,最后一个放置第二个机架上的另一个节点上。这种策略减少了机架间的通信,从而提高写入性能。机架故障的概率远小于节点故障的概率,这种策略不会影响数据可靠性和可用性。但是,它会降低读取数据的网络带宽,因为数据块放置在两个机架上,而不是三个。使用这种策略,副本不会均匀的分布在机架中。还有一种比较好的策略,就是三分之一的副本在一个节点上,三分之一的副本在另一个机架上,其余的均匀分布在其他机器上,这种方式可以改善写入策略,不会影响数据可靠性或读取性能。不过这种方式还在开发中。
3.2 副本选择
为了最大限度的减少全局带宽消耗和读取延迟,HDFS尝试让读取器读取最接近的副本。如果在同一机架上存在副本,就优先读取该副本。如果HDFS跨越多个数据中心,则优先读取当前数据中心的副本。
3.3 安全模式(SafeMode)
在启动的时候,NameNode进入一个成为安全模式的特殊状态。NameNode处于安全模式时,不会复制数据块。NameNode从DataNode节点接收心跳和数据块报告,数据块报告包含DataNode存储的数据块列表信息。每个数据块有指定的最小数量副本。当使用NameNode检入该数据块的最小副本数量时,数据块被认为是安全复制的。在NameNode检查数据块的安全复制结束后(可配的时间段,再加上30秒),NameNode退出安全模式。然后它开始检查是否有少于指定数量的数据块列表,将这些数据块复制到其他DataNode。
4. 文件系统元数据
HDFS由NameNode存储命名空间信息,NameNode使用名为EditLog的事务日志持续记录文件系统元数据发生的每个更改。比如,在HDFS中创建一个新的文件会导致NameNode在EditLog中插入一条记录,用于记录该操作。同样的,修改文件的复制因子也会新增一条记录。NameNode使用本机文件系统存储EditLog文件。整个文件系统命名空间(包括块映射文件和文件系统属性等信息)存储在一个名为FsImage的文件中,该文件也是存储在NameNode所在的本机文件系统中。
NameNode在内存中存储整个文件系统的命名空间和文件数据块映射关系,这个元数据存储模块设计为紧凑存储,可以在4GB内存的NameNode中可以支持大量的文件和文件夹。在NameNode启动时,它从磁盘读取FsImage和EditLog,将所有从EditLog的事务应用到FsImage的内存表示中,并将这个新版本的FsImage文件中。该操作会截断旧的EditLog,因为其中的事务操作已经应用到FsImage文件中。这个过程成为检查点(checkpoint)。在当前版本中,检查点操作只会发生在NameNode启动时,正在增加定期检查点检查操作。
DataNode将HDFS数据存储在其本地文件系统的文件中,DataNode不知道HDFS的文件数据,它只是将HDFS文件数据的数据块存储在本地文件系统中的单独文件中。DataNode不会存储同一文件夹下的所有文件,相反,它会确定每个文件夹的最佳文件数量,并适当的创建子文件夹。在同一文件夹中创建所有本地文件是不合适的,因为本地文件系统可能无法在单个文件夹中有效支持存储大量文件。当DataNode启动时,它会扫描其本地文件系统,生产与每个文件对应的所有HDFS数据块数控报告,并发送给NameNode。
5. 通信协议
所有HDFS的通信协议是基于TCP/IP协议的。客户端通过客户端协议与NameNode建立连接,并通信。DataNode通过DataNode协议与NameNode通信。NameNode从不发起通信请求,它只响应客户端和DataNode发出的请求。
6. 稳健性
HDFS的主要目标是可靠性存储,即使发生故障,也能够很好的支撑存储。比较常见的故障类型有:NameNode故障、DataNode故障、网络分区异常。
6.1 数据磁盘故障,心跳和重新复制
每个DataNode会定期向NameNode发送心跳请求。网络分区可能导致一部分DataNode与NameNode失去连接,NameNode通过心跳检测这种情况,如果发现长时间没有心跳的DataNode,则标记为丢弃,而且不再转发任何新的IO请求,这些DataNode的数据也不在作用于HDFS。DataNode的死亡可能导致某些数据块的复制因子低于设定值,NameNode会不断扫描哪些数据块需要复制,并在必要的时候进行复制。重复复制可能是因为DataNode不可用、副本文件损坏、DataNode硬盘损坏,或者文件复制因子增加。
6.2 集群重新平衡
HDFS架构与数据重新平衡方案兼容,如果DataNode上的可用空间低于阀值,数据会从一个DataNode移动到另一个DataNode。在对特定文件的需求突然增加的情况下,可能会动态创建其他副本来重新平衡集群中的数据。(这种类型的数据重新平衡还未实现)。
6.3 数据的完整性
DataNode存储的数据块可能会被破坏,这可能是因为存储设备故障、网络故障或软件错误导致的。HDFS客户端会对HDFS文件内容进行校验和检查。当客户端创建一个HDFS文件时,它会计算文件的每个块的检验码,然后将该校验码存储在同一HDFS命名空间中的隐藏文件中。当客户端操作文件时,会将从DataNode接收到的数据与存储的校验文件进行校验和匹配。如果没有成功,客户端会从该数据块的其他副本读取数据。
6.4 元数据磁盘故障
FsImage和EditLog是HDFS的核心数据结构,如果这些文件被损坏,可能导致HDFS实例不可用。因此,NameNode可以配置维护FsImage和EditLog的多个副本。对FsImage或EditLog的任何更新,这些副本也跟着更新。当时这样可能会导致NameNode的TPS。但是,这种性能的降低是可以接受的,因为即使HDFS应用程序本质上是数据密集型,但却不是元数据密集型的。当NameNode重启时,它会选择最新的FsImage和EditLog使用。
比较常见的多备份存储是一份存在本地文件系统中,一份存储在远程网络文件系统中。
因为NameNode单点的,所以可能会出现HDFS集群的单点故障,需要手动干预。这个时候就需要NameNode的HA方案,这个后面再说。
6.5 Secondary NameNode
前面说过,NameNode是单点的,如果NameNode宕机,系统中的文件会丢失,所以Hadoop提供还提供了一种机制:Secondary NameNode。
Secondary NameNode比较有意思,它并不能直接作为NameNode使用,它只是定期将FsImage和EditLog合并,防止EditLog文件过大。通常Secondary NameNode也是运行在单独的机器上,因为日志合并操作需要占用大量的内存和CPU。Secondary NameNode会保存合并后的元数据,一旦NameNode宕机,而且元数据不可用,就可以使用Secondary NameNode备份的数据。
但是,Secondary NameNode总是落后与NameNode,所以在NameNode宕机后,数据丢失是不可避免的。一般这种情况就会使用元数据的远程备份与Secondary NameNode中的合并数据共同作为NameNode的元数据文件。
6.6 快照
快照功能支持在特定时刻存储数据副本,可以在出现数据损坏的情况下,将HDFS回滚到之前的时间点。(目前还不支持,之后会增加)
7 数据
7.1 数据块
HDFS是为了存储大文件的。与HDFS兼容的程序是处理大型数据集的,这些应用通常是一次写入,多次读取,并且要求在读取速率上满足要求。HDFS恰好满足“一次写入、多次读取”的要求。在HDFS中,数据块大小默认是64MB。所以,大文件在HDFS内存切成64MB的数据块,每个数据块会存储在不同的DataNode上。
7.2 阶段
客户端创建文件的请求不会立即到达NameNode。一开始,客户端将文件缓存到临时文件中,写入操作透明的重定向到该临时文件中。当临时文件超过一个HDFS数据块的大小时,客户端将连接NameNode,NameNode会把文件名插入到文件系统中,为其分配一个数据块。NameNode使用DataNode和目标数据块响应客户端请求。然后客户端将数据块信息从本地临时文件刷新到指定的DataNode中。关闭文件时,临时文件中剩余的未刷新数据将传输到DataNode,然后,客户端通知NameNode文件关闭,此时,NameNode将文件创建操作提交到持久存储。如果NameNode在文件关闭前宕机, 则文件丢失。
HDFS采用上述方式是经过仔细考虑的,这些应用需要流式写入文件,如果客户端写入远程文件时没有使用客户端缓冲,网速和网络情况将会大大影响吞吐率。这种做法也是有先例的,早起的分布式文件系统也是采用这种方式,比如ASF。POSIX要求已经放宽,以便实现高性能的数据上传。
7.3 复制流水线
如上所述,当客户端数据写入HDFS时,首先将数据写入本地缓存文件。如果HDFS文件的复制因子是3,当本地缓存文件大小累积到数据块大小时,客户端从NameNode查询写入副本的DataNode列表。然后,客户端将数据块刷新到第一个DataNode中,这个DataNode以小数据(4KB)接收数据,将数据写入本地存储库,并将该部分数据传输到第二个DataNode,第二个DataNode存储后,将数据发送给第三个DataNode。因此,DataNode可以在流水线中接收来自前一个的数据,同时将数据发送给流水线的下一个,以此类推。
8 易使用
可以以多种方式访问HDFS,HDFS提供了一个Java API,C语言包装器也可用。也可以使用浏览器浏览HDFS实例文件。(目前正在通过使用WebDAV协议公开HDFS)。
8.1 FS Shell
HDFS允许以文件和文件夹的形式组织数据,提供了一个名为“FS shell”的命令行界面,可让用户与HDFS中的数据进行交互。该命令集语法类似与用户熟悉的其他shell(比如bash,csh)。以下是一些实例:
| 操作 | 命令 |
|---|---|
| 创建/foodir文件夹 | bin/hadoop dfs -mkdir /foodir |
| 删除/foodir文件夹 | bin/hadoop fs -rm -R /foodir |
| 查看文件/foodir/myfile.txt的内容 | bin/hadoop dfs -cat /foodir/myfile.txt |
FS shell针对需要脚本语言与存储数据进行交互的应用场景。
8.2 DFSAdmin
DFSAdmin命令集用于管理HDFS集群,这些应该是由HDFS管理员使用的命令,以下是一些实例:
| 操作 | 命令 |
|---|---|
| 集群置为安全模式 | bin/hadoop dfsadmin -safemode enter |
| 生成DataNode列表 | bin/hadoop dfsadmin -report |
| 启动或停止DataNode | bin/hadoop dfsadmin -refreshNodes |
8.3 浏览器接口
典型的HDFS安装会配置web服务器,以配置TCP端口公开HDFS命名空间,这允许用户浏览HDFS命名空间,并使用web浏览器查看文件内容。
9 空间复用
9.1 文件删除
如果回收站功能可用,通过FS Shell删除的文件不会立马删除,而是移动到回收站中(每个用户的回收文件夹不同,是在各自的用户目录的.Trash中,即/user/
大多数的删除文件会移动到回收站的current目录(即/user/
文件在回收站的时间过期后,NameNode会从HDFS命名空间中删除文件,同时,释放相关联的数据块空间。
文件删除后,客户端可以取消删除。可以通过浏览/trash文件夹,查找文件。/trash文件夹中包含被删除文件的最新副本。目前HDFS会从/trash删除超过6小时的文件。(/trash类似于文件系统中的回收站、垃圾桶等功能)。
下面是使用FS Shell删除文件的操作:
在当前目录中创建两个文件:test1、test2
$ hadoop fs -mkdir -p delete/test1
$ hadoop fs -mkdir -p delete/test2
$ hadoop fs -ls delete/
Found 2 items
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 delete/test1
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:40 delete/test2删除test1:
$ hadoop fs -rm -r delete/test1
Moved: hdfs://localhost:8020/user/hadoop/delete/test1 to trash at: hdfs://localhost:8020/user/hadoop/.Trash/Current使用skipTrash选项删除test2:
$ hadoop fs -rm -r -skipTrash delete/test2
Deleted delete/test2查看回收站中的文件只有test1:
$ hadoop fs -ls .Trash/Current/user/hadoop/delete/
Found 1 items\
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 .Trash/Current/user/hadoop/delete/test1也就是test1进入回收站,test2之间删除了。
9.2 减少复制因子
当文件的复制因子减少后,NameNode选择可以删除的多余副本,在下一个心跳时将信息传输给DataNode,DataNode删除相应的数据块,并释放空间。调用setReplication API和集群使用可用空间可能会有延迟。
参考
个人主页: https://www.howardliu.cn
个人博文: HDFS架构
CSDN主页: http://blog.csdn.net/liuxinghao
CSDN博文: HDFS架构